Appearance
前端性能相关问题
前端模块化
参考链接:
详解:
模块化为了解决 js 相互引用产生的问题,如:
- 顺序引入:先引入 jquery,才能引入其它 js
- 同步加载:1.js 加载并执行完,才加载 2.js
- window 全局变量污染
模块:
- 普通函数
- 对象
- 立即执行函数
在 webpack 出现前的 2 种前端模块化工具(代码模块化,执行上没有区别)
AMD:异步模块定义,使用 require.js,依赖前置
采用异步方式加载模块,模块的加载不影响它后面语句的运行,所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行,避免顺序引入和同步加载的问题。
- 用法:
javascript// 1.js 中(入口用require,其他用define) require([[2.js'], function(A) { // A得到的就是2.js模块的返回值 // 主要的执行代码 // 2.js 3.js都加载完,才执行1.js的这回调函数 }) // 2.js 中 define([[3.js', 'xxxx.js'], functionA(B, C) { // B得到的就是3.js模块的返回值,C是xxxx.js的 return aaaaa; // 2.js 模块的返回值 }) // 3.js 中 define([], functionA() { retrun {} // 3.js 模块的返回值 })原理:
块依赖加载之后,如何调用回调函数
使用 requireJs 时,都是在页面上只引入一个 require.js,把 data-main 指向我们的 main.js
运行 main.js 时,执行里面的 require 和 define 方法,requireJs 会把这些依赖和回调方法都用一个数据结构存起来
然后使用 script 来加载这些模块依赖,并且监听 load 函数,且每个 script 元素都会有一个自定义的属性,用来指明模块名
当模块加载成功之后,可以通过元素属性来获取模块名,接着通过模块名来获取模块的定义,接着对模块进行初始化,再对子模块重复操作
当子模块没有其他要加载的依赖的时候这个时候表明子模块已经加载完毕,调用回调函数
加载依赖之后,如何将接口暴露给回调函数
当执行回调函数的时候,会使用 apply 将模块定义中的接口,传递给回调函数
如何解决循环依赖的问题
将已定义的模块保存在一个对象中,当加载模块依赖的时候,如果在这个对象中存在的话,则直接返回这个模块。否则的话,则再走一遍加载的模块的流程。
代码:
javascriptvar modules = {}, // 存放所有文件模块的信息,每个js文件模块的信息 loadings = []; // 存放所有已经加载了的文件模块的id,一旦该id的所有依赖都加载完后,该id将会在数组中移除 // 上面说了,每个文件模块都要有个id,这个函数是返回当前运行的js文件的文件名,拿文件名作为文件对象的id // 比如,当前加载 3.js 后运行 3.js ,那么该函数返回的就是 '3.js' function getCurrentJs() { return document.currentScript.src } // 创建节点 function createNode() { var node = document.createElement('script') node.type = 'text/javascript' node.async = true; return node } // 开始运行 function init() { // 加载 1.js loadJs('1.js') } // 加载文件(插入dom中),如果传了回调函数,则在onload后执行回调函数 function loadJs(url, callback) { var node = createNode() node.src = url; node.setAttribute('data-id', url) node.addEventListener('load', function(evt) { var e = evt.target setTimeout(() => { // 这里延迟一秒,只是让在浏览器上直观的看到每1秒加载出一个文件 callback && callback(e) }, 1000) }, false) document.body.appendChild(node) } // 此时,loadJs(1.js)后,并没有传回调函数,所以1.js加载成功后只是自动运行1.js代码 // 而1.js代码中,是require( [[2.js', 'xxx.js'], functionA(B, C){} ),则执行的是require函数, 在下面是require的定义 window.require = function(deps, callback) { // deps 就是对应的 [[2.js', 'xxx.js'] // callback 就是对应的 functionA // 在这里,是不会运行callback的(即模块的运行!),得等到所有依赖都加载完的啊 // 所以得有个地方,把一个文件的所有信息都先存起来啊,尤其是deps和callback var id = getCurrentJs();// 当前运行的是1.js,所以id就是'1.js' if(!modules.id) { modules[id] = { // 该模块对象信息 id: id, deps: deps, callback: callback, exports: null, // 该模块的返回值return , 就是functionA(B, C)运行后的返回值,仔细想想?在后面的getExports中详细讲 status: 1, } loadings.unshift(id); // 加入这个id,之后会循环loadings数组,递归判断id所有依赖 } loadDepsJs(id); // 加载这个文件的所有依赖,即去加载[2.js] } function loadDepsJs(id) { var module = modules[id]; // 获取到这个文件模块对象 // deps是[[2.js'] module.deps.map(item => { // item 其实是依赖的Id,即 '2.js' if(!modules[i]) { // 如果这个文件没被加载过(注:加载过的肯定在modules中有) (1) loadJs(item, function() { // 加载 2.js,并且传了个回调,准备要递归了 // 2.js加载完后,执行了这个回调函数 loadings.unshift(item); // 此时里面有两个了, 1.js 和 2.js // 递归。。。要去搞3.js了 loadDepsJs(item)// item传的2.js,递归再进来时,就去modules中取2.js的deps了 // 每次检查一下,是否都加载完了 checkDeps(); // 循环loadings,配合递归嵌套和modules信息,判断是否都加载完了 }) } }) } // 上面(1)那里,加载了2.js后马上会运行2.js的,而2.js里面是 define([[js'], fn) // 所以相当于执行了 define函数 window.define = function(deps,callback) { var id = getCurrentJs() if(!modules.id) { modules[id] = { id: id, deps: getDepsIds(deps), callback: callback, exports: null, status: 1, } } } // 注意,define运行的结果,只是在modules中添加了该模块的信息 // 因为其实在上面的loadDepsJs中已经事先做了loadings和递归deps的操作,而且是一直不断的循环往复的进行探查,所以define里面就不需要再像require中写一次loadDeps了 // 循环loadings,查看loadings里面的id,其所依赖的所有层层嵌套的依赖模块是否都加载完了 function checkDeps() { for(var i = 0, id; i < loadings.length ; i++) { id = loadings[i] if(!modules[id]) continue var obj = modules[id], deps = obj.deps // 下面那行为什么要执行checkCycle函数呢,checkDeps是循环loadings数组的模块id,而checkCycle是去判断该id模块所依赖的**层级**的模块是否加载完 // 即checkDeps是**广度**的循环已经加载(但依赖没完全加载完的)的id // checkCycle是**深度**的探查所关联的依赖 // 还是举例吧。。。假如除了1.js, 2.js, 3.js, 还有个4.js,依赖5.js,那么 // loadings 可能 是 [[1.js', '4.js'] // 所以checkDeps --> 1.js, 4.js // checkCycle深入内部 1.js --> 2.js --> 3.js ;;; 4.js --> 5.js // 一旦比如说1.js的所有依赖2.js、3.js都加载完了,那么1.js 就会在loadings中移出 var flag = checkCycle(deps) if(flag) { console.log(i, loadings[i] ,'全部依赖已经loaded'); loadings.splice(i,1); // !!!运行模块,然后同时得到该模块的返回值!!! getExport(obj.id) // 不断的循环探查啊~~~~ checkDeps() } } } // 深层次的递归的去判断,层级依赖是否都加在完了 // 进入1.js的依赖2.js,再进入2.js的依赖3.js ...... function checkCycle(deps) { var flag = true function cycle(deps) { deps.forEach(item => { if(!modules[item] || modules[item].status == 1) { flag = false } else if(modules[item].deps.length) { // console.log('inner deps', modules[item].deps); cycle(modules[item].deps) } }) } cycle(deps) return flag } /* 运行该id的模块,同时得到模块返回值,modules[id].export */ function getExport(id) { /* 先想一下,例如模块2.js, 这时 id == 2.js define([[3.js', 'xxxx.js'], functionA(B, C) { // B得到的就是3.js模块的返回值,C是xxxx.js的 return aaaaa // 2.js 模块的返回值 }) 所以: 1. 运行模块,就是运行 functionA (模块的callback) 2. 得到模块的返回值,就是functionA运行后的返回值 aaaaa 问题: 1. 运行functionA(B, C) B, C是什么?怎么来的? 2. 有B, C 了,怎么运行functionA ? */ // 解决问题1 // B, C 就是该模块依赖 deps [3.js, xxxx.js]对应的返回值 // 那么循环deps 得到 依赖模块Id, 取模块的export var params = []; var deps = modules[id].deps for(var i = 0; i < deps.length; i++) { // 取依赖模块的exports即模块返回值,注意不要害怕取不到,因为你这个模块都进来打算运行了,那么你的所有依赖的模块早都进来过运行完了(还记得模块运行顺序不?) let depId = deps[i] params.push( modules[ depId ].exports ) } // 到这里,params就是依赖模块的返回值的数组,也就是B,C对应的实参 // 也就是 params == [3.js的返回值,xxxx.js的返回值] if(!modules[id].exports) { // 解决问题2: callback(functionA)的执行,用.apply,这也是为什么params是个数组了 // 这一行代码,既运行了该模块,同时也得到了该模块的返回值export modules[id].exports = modules[id].callback.apply(global, params) } }模块运行顺序:
3.js,2.js,1.js,如果模块以及该模块的依赖都加载完,就执行。 如 3.js 加载完后,没有依赖,直接执行 3.js 的回调了,2.js 加载完后探查到依赖的 3.js 也加载完,2.js 执行自己的回调了,主模块一定在最后执行
CMD:通用模块定义,使用sea.js,依赖就近
- 用法:
javascript// 只有define,没有require // 和AMD那个例子一样,还是1依赖2, 2依赖3 //1.js中 define(function() { var a = require('2.js') console.log(33333) var b = require('4.js') }) //2.js 中 define(function() { var b = require('3.js') }) //3.js 中 define(function() { // xxx })原理同AMD
模块运行顺序:
1.js,2.js,3.js,即先执行主模块1.js,碰到require('2.js')就执行2.js,2.js中碰到require('3.js')就执行3.js
es6模块化与commonjs区别
es6模块化:import-export,编译时加载 commonjs:require,module.exports=对象/函数,运行时加载
服务器端模块化工具
webpack基于CommonJs
同步加载
一个单独的文件就是一个模块,每一个模块都是一个单独的作用域,在该模块内部定义的变量,无法被其他模块读取,除非定义为global对象的属性。
加载模块使用require方法,该方法读取一个文件并执行,返回文件内部的module.exports对象,用来输出模块。
模块化代码示例
amd
javascriptdefine([[jquery', 'underscore'], function ($, _) { // methods function a(){}; // private because it's not returned (see below) function b(){}; // public because it's returned function c(){}; // public because it's returned // exposed public methods return { b: b, c: c } });commonjs
javascript// dependencies var $ = require('jquery'); // methods function myFunc(){}; // exposed public method (single) module.exports = myFunc;umd(amd和commonjs的统一规范)
javascript(function (root, factory) { if (typeof define === 'function' && define.amd) { // AMD define([[jquery', 'underscore'], factory); } else if (typeof exports === 'object') { // Node, CommonJS-like module.exports = factory(require('jquery'), require('underscore')); } else { // Browser globals (root is window) root.returnExports = factory(root.jQuery, root._); } }(this, function ($, _) { // methods function a(){}; // private because it's not returned (see below) function b(){}; // public because it's returned function c(){}; // public because it's returned // exposed public methods return { b: b, c: c } }));ESM
javascriptimport React from 'react';
问题
为什么:每个模块文件上存在 module,exports,require三个变量,然而这三个变量是没有被定义的,但是我们可以在 Commonjs 规范下每一个 js 模块上直接使用它们?
在编译的过程中,实际 Commonjs 对 js 的代码块进行了首尾包装,会形成一个包装函数,我们写的代码将作为包装函数的执行上下文,使用的 require ,exports ,module 本质上是通过形参的方式传递到包装函数中的。
javascript//module 记录当前模块信息。 //require 引入模块的方法。 //exports 当前模块导出的属性 function wrapper (script) { return '(function (exports, require, module, __filename, __dirname) {' + script + '\n})' }require 大致流程
require 会接收一个参数——文件标识符,然后分析定位文件,从 Module 上查找有没有缓存,如果有缓存,那么直接返回缓存的内容。
如果没有缓存,会创建一个 module 对象,缓存到 Module 上,然后执行文件,加载完文件,将 loaded 属性设置为 true ,然后返回 module.exports 对象。借此完成模块加载流程。
require 如何避免重复加载?
加载之后的文件的 module 会被缓存到 Module 上,如果另外一个模块再次引用 ,那么会直接读取缓存值 module ,所以无需再次执行模块。
require 如何避免循环引用?
将已定义的module保存在一个对象Module中,当加载模块依赖的时候,如果在这个对象Module中存在的话,则直接返回这个模块。否则的话,则再走一遍加载的模块的流程。
为什么 exports={} 直接赋值一个对象就不可以呢?必须exports.xxx=***
exports , module 和 require 作为形参的方式传入到 js 模块中,直接 exports = {} 修改 exports ,等于重新赋值了形参,那么会重新赋值一份,但是不会在引用原来的形参。
形如
javascriptfunction wrap (myExports){//Commonjs 规范下的包装函数,里面是我们需要写的代码 myExports={ name:'我不是外星人' } } let myExports = { name:'alien' } wrap(myExports) console.log(myExports)//{name:'alien'}既然有了 exports,为何又出了 module.exports ?
module.exports 本质上就是 exports,持有相同引用,module.exports 也可以单独导出一个函数或者一个类。
module.exports和exports不能同时存在,否则会覆盖数据。
module.exports可以直接赋值函数或对象,而exports只能赋值于对象属性。
显然module.exports会更加便利。
与 exports 相比,module.exports 有什么缺陷 ?
module.exports 当导出一些函数等非对象属性的时候,也有一些风险,就比如循环引用的情况下。对象会保留相同的内存地址,就算一些属性是后绑定的,也能间接通过异步形式访问到。但是如果 module.exports 为一个非对象其他属性类型,在循环引用的时候,就容易造成属性丢失的情况。
Commonjs 的特性
- CommonJS 模块由 JS 运行时实现。
- CommonJs 是单个值导出,本质上导出的就是 exports 属性。
- CommonJS 是可以动态加载的,对每一个加载都存在缓存,可以有效的解决循环引用问题。
- CommonJS 模块同步加载并执行模块文件。
Es module 的特性
- ES6 Module 静态的,不能放在块级作用域内,代码发生在编译时。
- ES6 Module 的值是动态绑定的,可以通过导出方法修改,可以直接访问修改结果。
- ES6 Module 可以导出多个属性和方法,可以单个导入导出,混合导入导出。
- ES6 模块提前加载并执行模块文件,
- ES6 Module 导入模块在严格模式下。
- ES6 Module 的特性可以很容易实现 Tree Shaking 和 Code Splitting。
gulp和webpack
参考链接:
webpack4.x 配置详解,多页面,拆分代码,多入口,多出口,新特性新坑
vue 项目中使用 webpack 优化之 HappyPack 实战
详解:
webpack 与 grunt、gulp 的不同
grunt 和 gulp 是基于任务和流(Task、Stream),整条链式操作构成了一个任务,多个任务形成构建过程
webpack 是基于入口的。webpack 会自动地递归解析入口所需要加载的所有资源文件,然后用不同的 Loader 来处理不同的文件,用 Plugin 来扩展 webpack 功能
与 webpack 类似的工具还有哪些
- webpack 适用于大型复杂的前端站点构建
- rollup 适用于基础库的打包,如 vue、react
- parcel 适用于简单的实验性项目,他可以满足低门槛的快速看到效果
- 由于 parcel 在打包过程中给出的调试信息十分有限,所以一旦打包出错难以调试,所以不建议复杂的项目使用 parcel
有哪些常见的 Loader
- file-loader:把文件输出到一个文件夹中,在代码中通过相对 URL 去引用输出的文件
- url-loader:和 file-loader 类似,但是能在文件很小的情况下以 base64 的方式把文件内容注入到代码中去
- source-map-loader:加载额外的 Source Map 文件,以方便断点调试
- image-loader:加载并且压缩图片文件
- babel-loader:把 ES6 转换成 ES5
- css-loader:加载 CSS,支持模块化、压缩、文件导入等特性
- style-loader:把 CSS 代码注入到 JavaScript 中,通过 DOM 操作去加载 CSS。
- eslint-loader:通过 ESLint 检查 JavaScript 代码
- sass-loader:把 sass 转换为 css
- 更多
有哪些常见的 Plugin
- define-plugin:定义环境变量
- commons-chunk-plugin:提取公共代码
- uglifyjs-webpack-plugin:通过 UglifyES 压缩 ES6 代码
- HotModuleReplacementPlugin:热更新
- purifyCssWebpack:消除冗余的 css 代码
- 更多
Loader 和 Plugin 的不同
Loader 直译为"加载器"。Webpack 将一切文件视为模块,但是 webpack 原生是只能解析 js 文件,如果想将其他文件也打包的话,就会用到 loader。 所以 Loader 的作用是让 webpack 拥有了加载和解析非 JavaScript 文件的能力。
Plugin 直译为"插件"。Plugin 可以扩展 webpack 的功能,让 webpack 具有更多的灵活性。 在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。
不同的用法
Loader 在 module.rules 中配置,作为模块的解析规则而存在。类型为数组,每一项都是一个 Object,里面描述了对于什么类型的文件(test),使用什么加载(loader)和使用的参数(options)
Plugin 在 plugins 中单独配置。类型为数组,每一项是一个 plugin 的实例,参数都通过构造函数传入。
webpack运行原理
- 解析入口文件entry,将其转为AST(抽象语法树),使用@babel/parser
- 然后使用@babel/traverse去找出入口文件所有依赖模块
- 然后使用@babel/core+@babel/preset-env将入口文件的AST转为Code
- 将2中找到的入口文件的依赖模块,进行遍历递归,重复执行1,2,3
- 重写require函数,并与4中生成的递归关系图一起,输出到bundle中
webpack 的构建流程是什么?从读取配置到输出文件这个过程尽量说全
运行前,需要先使用命令 npm init 构建 package.json 配置文件,npm install 相关的 module,scripts 中编写运行命令,最后 npm run ***运行
javascript{ "name": "react-family", "version": "1.0.0", "description": "learn react-family", "main": "src/index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1", "build": "webpack --config webpack.dev.config.js" }, "author": "...", "license": "ISC", "devDependencies": { "babel-cli": "^6.26.0", "babel-core": "^6.26.0", "babel-loader": "^7.1.2", "babel-preset-env": "^1.6.1", "babel-preset-es2015": "^6.24.1", "babel-preset-react": "^6.24.1", "babel-preset-stage-0": "^6.24.1", "webpack": "^3.10.0" }, "dependencies": {} }Webpack 的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
- 初始化参数:从配置文件和 Shell 语句中读取与合并参数,得出最终的参数;
- 开始编译:用上一步得到的参数初始化 Compiler 对象,加载所有配置的插件,执行对象的 run 方法开始执行编译;
- 确定入口:根据配置中的 entry 找出所有的入口文件;
- 编译模块:从入口文件出发,调用所有配置的 Loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理;
- 完成模块编译:Loader 翻译完所有模块后,得到了每个模块的最终内容以及它们之间的依赖关系;
- 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会;
- 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
在以上过程中,Webpack 会在特定的时间点广播出特定的事件(详见下方“插件样例”),插件在监听到定义的事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果。
描述一下编写 loader 或 plugin 的思路
Loader 像一个"翻译官"把读到的源文件内容转义成新的文件内容,并且每个 Loader 通过链式操作,将源文件一步步翻译成想要的样子。
编写 Loader 时要遵循单一原则,每个 Loader 只做一种"转义"工作。 每个 Loader 拿到的是源文件内容(source),可以通过返回值的方式将处理后的内容输出,也可以调用 this.callback()方法,将内容返回给 webpack。 还可以通过 this.async()生成一个 callback 函数,再用这个 callback 将处理后的内容输出出去。 此外 webpack 还为开发者准备了开发 loader 的工具函数集——loader-utils。
相对于 Loader 而言,Plugin 的编写就灵活了许多。 webpack 在运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。
如何利用 webpack 来优化前端性能
压缩代码。删除多余的代码、注释、简化代码的写法等等方式。可以利用 webpack 的 UglifyJsPlugin 和 ParallelUglifyPlugin 来压缩 JS 文件, 利用 cssnano(css-loader?minimize)来压缩 css
利用 CDN 加速。在构建过程中,将引用的静态资源路径修改为 CDN 上对应的路径。可以利用 webpack 对于 output 参数和各 loader 的 publicPath 参数来修改资源路径
删除死代码(Tree Shaking)。将代码中永远不会走到的片段删除掉。可以通过在启动 webpack 时追加参数--optimize-minimize 来实现
提取公共代码。
如何提高 webpack 的构建速度
多入口情况下,使用 CommonsChunkPlugin 来提取公共代码
通过 externals 配置来提取常用库
利用 DllPlugin 和 DllReferencePlugin 预编译资源模块,通过 DllPlugin 来对那些我们引用但是绝对不会修改的 npm 包来进行预编译,再通过 DllReferencePlugin 将预编译的模块加载进来。
使用 Happypack 实现多线程加速编译(webpack4 弃用见下方)
使用 webpack-uglify-parallel 来提升 uglifyPlugin 的压缩速度。 原理上 webpack-uglify-parallel 采用了多核并行压缩来提升压缩速度
使用 Tree-shaking(删除项目中未被引用的代码) 和 Scope Hoisting(代码就会尽可能的合并到一个函数中去) 来剔除多余代码
Tree-shaking会自动开启
Scope Hoisting
javascriptmodule.exports = { optimization: { concatenateModules: true } }
怎么配置单页应用?怎么配置多页应用?
单页应用可以理解为 webpack 的标准模式,直接在 entry 中指定单页应用的入口即可
多页应用可以使用 webpack 的 AutoWebPlugin 来完成简单自动化的构建,但是前提是项目的目录结构必须遵守他预设的规范。 多页应用中要注意的是:
每个页面都有公共的代码,可以将这些代码抽离出来,避免重复的加载。比如,每个页面都引用了同一套css样式表 随着业务的不断扩展,页面可能会不断的追加,所以一定要让入口的配置足够灵活,避免每次添加新页面还需要修改构建配置npm 打包时需要注意哪些?如何利用 webpack 来更好的构建
npm 是目前最大的 JavaScript 模块仓库,里面有来自全世界开发者上传的可复用模块。你可能只是 JS 模块的使用者,但是有些情况你也会去选择上传自己开发的模块。 关于 NPM 模块上传的方法可以去官网上进行学习,这里只讲解如何利用 webpack 来构建。
- NPM 模块需要注意以下问题:
- 要支持 CommonJS 模块化规范,所以要求打包后的最后结果也遵守该规则。
- Npm 模块使用者的环境是不确定的,很有可能并不支持 ES6,所以打包的最后结果应该是采用 ES5 编写的。并且如果 ES5 是经过转换的,请最好连同 SourceMap 一同上传。
- Npm 包大小应该是尽量小(有些仓库会限制包大小)
- 发布的模块不能将依赖的模块也一同打包,应该让用户选择性的去自行安装。这样可以避免模块应用者再次打包时出现底层模块被重复打包的情况。
- UI 组件类的模块应该将依赖的其它资源文件,例如.css 文件也需要包含在发布的模块里。
- 基于以上需要注意的问题,我们可以对于 webpack 配置做以下扩展和优化:
- CommonJS 模块化规范的解决方案: 设置 output.libraryTarget='commonjs2'使输出的代码符合 CommonJS2 模块化规范,以供给其它模块导入使用
- 输出 ES5 代码的解决方案:使用 babel-loader 把 ES6 代码转换成 ES5 的代码。再通过开启 devtool: 'source-map'输出 SourceMap 以发布调试。
- npm 包大小尽量小的解决方案:Babel 在把 ES6 代码转换成 ES5 代码时会注入一些辅助函数,最终导致每个输出的文件中都包含这段辅助函数的代码,造成了代码的冗余。解决方法是修改.babelrc 文件,为其加入 transform-runtime 插件
- 不能将依赖模块打包到 NPM 模块中的解决方案:使用 externals 配置项来告诉 webpack 哪些模块不需要打包。
- 对于依赖的资源文件打包的解决方案:通过 css-loader 和 extract-text-webpack-plugin 来实现,配置如下:
javascriptconst ExtractTextPlugin = require ('extract-text-webpack-plugin'); module.exports = { module: { rules:[ { //增加对CSS文件的支持 test:/\.css/, // 提取出Chunk中的CSS代码到单独的文件中 use: ExtractTextPlugin.extract({ use: [[css-loader'] }), }, ] }, plugins:[ new ExtractTextPlugin({ // 输出的CSS文件名称 filenames 'index.css' }) ] }如何在 vue 项目中实现按需加载
Vue UI 组件库的按需加载为了快速开发前端项目,经常会引入现成的 UI 组件库如 ElementUI、iView 等,但是他们的体积和他们所提供的功能一样,是很庞大的。 而通常情况下,我们仅仅需要少量的几个组件就足够了,但是我们却将庞大的组件库打包到我们的源码中,造成了不必要的开销。
不过很多组件库已经提供了现成的解决方案,如 Element 出品的 babel-plugin-component 和 AntDesign 出品的 babel-plugin-import 安装以上插件后,在.babelrc 配置中或 babel-loader 的参数中进行设置,即可实现组件按需加载了。
单页应用的按需加载 现在很多前端项目都是通过单页应用的方式开发的,但是随着业务的不断扩展,会面临一个严峻的问题——首次加载的代码量会越来越多,影响用户的体验。
详见“vue 简结”-“注意或优化的地方”-“babel”
通过 import()语句来控制加载时机,webpack 内置了对于 import()的解析,会将 import()中引入的模块作为一个新的入口在生成一个 chunk。 当代码执行到 import()语句时,会去加载 Chunk 对应生成的文件。import()会返回一个 Promise 对象,所以为了让浏览器支持,需要事先注入 Promise polyfill
详见“vue 简结”-“动态组件与异步组件”
webpack异步加载原理
webpack4 官方文档提供了模块按需切割加载,配合 es6 的按需加载 import() 方法,可以做到减少首页包体积,加快首页的请求速度,只有其他模块,只有当需要的时候才会加载对应 js。
import()的语法十分简单。该函数只接受一个参数,就是引用包的地址,并且使用了 promise 式的回调,获取加载的包。在代码中所有被 import()的模块,都将打成一个单独的包,放在 chunk 存储的目录下。在浏览器运行到这一行代码时,就会自动请求这个资源,实现异步加载。
经过 webpack 打包,每一个 chunk 内的模块文件,都是组合成形如
javascript(function(modules){ //.... })({ [moduleName:string] : function(module, __webpack_exports__, __webpack_require__){ eval('模块文件源码') } })在立即执行函数的入参modules上挂上别的 webpack 环境异步加载的部分模块代码。
采用 jsonp 的方式来实现模块的异步加载
项目依赖同一npm包的多版本,会有冲突吗?
项目trade,依赖了[email protected]版本。 然后我又引入了B,而B依赖[email protected]版本,这时候会产生冲突吗?
不会有冲突,因为这种场景太常见了。
node_modules中包的下载安装目录
trade ├─ [email protected] └┬ B └─ [email protected]webpack生成bundle,打包的策略:import的模块都叫做A,但是webpack内部,是把模块的路径当做模块的id标识来区分的,所以就不会找错了
javascript// webpack模块的管理 { "./node_modules/A/index.min.js": function() {}, "./node_modules/B/node_modules/A/index.min.js": function() {} }gulp 配置
//.babelrc { "presets": [ "es2015" ] }javascript//3.9.0 var gulp = require("gulp"), sass = require("gulp-sass"), autoprefixer = require("gulp-autoprefixer"), minifycss = require("gulp-minify-css"), imagemin = require("gulp-imagemin"), babel = require("gulp-babel"), jshint = require("gulp-jshint"), concat = require("gulp-concat"), uglify = require("gulp-uglify"), livereload = require("gulp-livereload"), notify = require("gulp-notify"), cache = require("gulp-cache"), rename = require("gulp-rename"), del = require("del"); gulp.task('scripts', function() { gulp.src('src/js/Home/*.js') .pipe(babel())//转译es5,需配置.babelrc .pipe(uglify())//压缩 .pipe(rename({ suffix: '.min' }))//重命名为*.min.js .pipe(gulp.dest('Content/themes/base/minjs/Home'))//输出文件到指定位置 .pipe(notify({ message: 'Home js task complete'//控制台输出任务完成 })); gulp.src('src/js/Shared/*.js') .pipe(babel()) .pipe(uglify()) .pipe(rename({ suffix: '.min' })) .pipe(gulp.dest('Content/themes/base/minjs/Shared')) .pipe(notify({ message: 'Shared js task complete' })); }); gulp.task('styles', function() { gulp.src('src/scss/Home/*.scss') .pipe(sass())//编译sass .pipe(autoprefixer('last 2 version', 'safari 8', 'ie 8', 'ie 9', 'opera 12.1', 'ios 6', 'android 4'))//自动添加prefix适配 .pipe(minifycss())//压缩 .pipe(rename({ suffix: '.min' }))//重命名为*.min.css .pipe(gulp.dest('Content/themes/base/css/Home'))//输出文件到指定位置 .pipe(notify({ message: 'Home css task complete'//控制台输出任务完成 })); gulp.src('src/scss/Shared/*.scss') .pipe(sass()) .pipe(autoprefixer('last 2 version', 'safari 5', 'ie 8', 'ie 9', 'opera 12.1', 'ios 6', 'android 4')) .pipe(minifycss()) .pipe(rename({ suffix: '.min' })) .pipe(gulp.dest('Content/themes/base/css/Shared')) .pipe(notify({ message: 'Shared css task complete' })); }); gulp.task('auto', function() { gulp.watch([[src/js/*/*.js'], [[scripts']);//监听文件变化 gulp.watch([[src/scss/*/*.scss'], [[styles']); }); gulp.task('default', [[styles', 'scripts', 'auto']);- gulp 打包报错不中断
javascript//npm install -D gulp-plumber var plumber = require('gulp-plumber'); gulp.src(src_dir + "/scripts/**/*.js") .pipe(plumber()) //优先使用plumber() .pipe(jshint()) .pipe(jshint.reporter('default')); gulp.src(dist_dir + "/templates/**/*.html") .pipe(plumber()) .pipe(htmlmin({ collapseWhitespace: true })) .pipe(templateCache("tpl.min.js", { module: "xt.templates", standalone: true })) .pipe(gulpif(isUglify, uglify())) .pipe(gulp.dest(dist_dir + "/scripts/"));gulp 使用babel-polyfill
gulp无法像webpack一样打包出浏览器能识别的代码,gulp-babel只能将es6语法编译成es5,比如:箭头函数、let变量等,但是API不能编译,比如Object.assign,因此需要手动在html中引入polyfill的js(babel-polyfill)
https://cdn.bootcss.com/babel-polyfill/7.0.0-rc.4/polyfill.min.js
- webpack配置
"dev": "webpack --mode=development", "build": "webpack --mode=production", "start": "webpack-dev-server"完全配置
javascriptconst webpack = require("webpack"); const path = require('path'); //返回匹配指定模式的文件名或目录 const glob = require("glob"); //消除冗余的css const purifyCssWebpack = require("purifycss-webpack"); // html模板 const htmlWebpackPlugin = require("html-webpack-plugin"); // 清除目录等 const cleanWebpackPlugin = require("clean-webpack-plugin"); //4.x之前用以压缩 const uglifyjsWebpackPlugin = require("uglifyjs-webpack-plugin"); //ES压缩 const UglifyESPlugin = require('uglify-webpack-plugin'); // 分离css const extractTextPlugin = require("extract-text-webpack-plugin"); //静态资源输出 const copyWebpackPlugin = require("copy-webpack-plugin"); module.exports = { entry: { // 多入口文件 a: './src/js/index.js', b: './src/js/index2.js', jquery: 'jquery' }, output: { path:path.resolve(__dirname, 'dist'), // 打包多出口文件 // 生成 a.bundle.js b.bundle.js jquery.bundle.js filename: './js/[name].bundle.js' }, // devtool: "source-map", // 开启调试模式 module:{ rules: [ { test: /\.css$/, // 不分离的写法 // use: ["style-loader", "css-loader"] // 使用postcss不分离的写法 // use: ["style-loader", "css-loader", "postcss-loader"] // 此处为分离css的写法 /*use: extractTextPlugin.extract({ fallback: "style-loader", use: "css-loader", // css中的基础路径 publicPath: "../" })*/ // 此处为使用postcss分离css的写法 // use: extractTextPlugin.extract({ // fallback: "style-loader", // use: ["css-loader", "postcss-loader"], // // css中的基础路径 // publicPath: "../" // }) //此处可配置压缩css use: [ { loader: 'style-loader' }, { loader: 'css-loader', options: { root: '/', //修改css中url指向的根目录, 默认值为/, 对于绝对路径, css-loader默认是不会对它进行处理的 modules: false, //开启css-modules模式, 默认值为flase localIdentName: '[name]-[local]-[hash:base64:5]', //设置css-modules模式下local类名的命名 minimize: false, //压缩css代码, 默认false camelCase: false, //导出以驼峰化命名的类名, 默认false import: true, //禁止或启用@import, 默认true url: true, //禁止或启用url, 默认true sourceMap: false, //禁止或启用sourceMap, 默认false importLoaders: 0, //在css-loader前应用的loader的数目, 默认为0 alias: {} //起别名, 默认{} } } ] }, { test: /\.js$/, use: ["babel-loader"], // 不检查node_modules下的js文件 exclude: "/node_modules/" }, { test: /\.(png|jpg|gif)$/, use: [{ // 需要下载file-loader和url-loader loader: "url-loader", options: { limit: 50, // 图片文件输出的文件夹 outputPath: "images" } } ] }, { test: /\.(png|jpg|gif|svg)$/, use: [ 'file-loader', { loader: 'image-webpack-loader', options: { bypassOnDebug: true, mozjpeg: { progressive: true, quality: 65 }, optipng: { enabled: false, }, pngquant: { quality: '65-90', speed: 4 }, gifsicle: { interlaced: false, }, // the webp option will enable WEBP webp: { enabled: false, }, limit: 1, name: '[name].[ext]?[hash]' } }] }, { test: /\.html$/, // html中的img标签 use: ["html-withimg-loader"] }, { test: /\.less$/, // 三个loader的顺序不能变 // 不分离的写法 // use: ["style-loader", "css-loader", "less-loader"] // 分离的写法 use: extractTextPlugin.extract({ fallback:"style-loader", use: ["css-loader", "less-loader"] }) }, { test: /\.(scss|sass)$/, // sass不分离的写法,顺序不能变 // use: ["style-loader", "css-loader", "sass-loader"] // 分离的写法 use: extractTextPlugin.extract({ fallback:"style-loader", use: ["css-loader", "sass-loader"] }) } ] }, plugins: [ new webpack.HotModuleReplacementPlugin(), // 调用之前先清除 new cleanWebpackPlugin(["dist"]), // 4.x之前可用uglifyjs-webpack-plugin用以压缩文件,4.x可用--mode更改模式为production来压缩文件 new UglifyJSPlugin({ compress: { warnings: false, //删除无用代码时不输出警告 drop_console: true, //删除所有console语句,可以兼容IE collapse_vars: true, //内嵌已定义但只使用一次的变量 reduce_vars: true, //提取使用多次但没定义的静态值到变量 }, output: { beautify: false, //最紧凑的输出,不保留空格和制表符 comments: false, //删除所有注释 } }), //ES压缩插件 new UglifyESPlugin({ uglifyOptions: { //比UglifyJS多嵌套一层 compress: { warnings: false, drop_console: true, collapse_vars: true, reduce_vars: true }, output: { beautify: false, comments: false } } }), new copyWebpackPlugin([{ from: path.resolve(__dirname,"src/assets"), to: './public' }]), // 分离css插件参数为提取出去的路径 new extractTextPlugin("css/index.css"), // 消除冗余的css代码 new purifyCssWebpack({ // glob为扫描模块,使用其同步方法 paths: glob.sync(path.join(__dirname, "src/*.html")) }), // 全局暴露统一入口 new webpack.ProvidePlugin({ $: "jquery" }), // 自动生成html模板 new htmlWebpackPlugin({ minify:{ removeAttributeQuotes:true//去掉双引号 }, hash:true,//加入哈希来禁止缓存 filename: "index.html",// 编译后的文件及路径 title: "xxxx", chunks: [[a',"jquery"], // 按需引入对应名字的js文件 template: "./src/index.html"// 源模板 }), new htmlWebpackPlugin({ chunks: [[b'], filename: "index2.html", title: "page2", template: "./src/index2.html" }) ], watch: true, watchOptions: { poll: 1000, // 每秒询问多少次 aggregateTimeout: 500, //防抖 多少毫秒后再次触发 ignored: /node_modules/ //忽略时时监听 } devServer: { contentBase: path.resolve(__dirname, "dist"), host: "localhost", port: "8090", open: true, // 开启浏览器 hot: true // 开启热更新 }, // 提取js,lib1名字可改 optimization: { splitChunks: { cacheGroups: { lib1: { chunks: "initial", name: "jquery", enforce: true } } } } }treeShaking
描述
解析js代码得出语法树,在保持代码运行结果不变的前提下,去除无用的代码(没有执行的代码,如不可能进入的if分支,return后的代码,声明后没用的变量),使用的是编译原理中提到的DCE(dead code eliminnation)
Tree-shaking是依赖ES6模块静态分析的,因为ES6 module只能作为模块顶层的语句出现,import 的模块名只能是字符串常量,import 绑定是不可改变的,依赖关系确定,与运行时无关
使用
使用插件压缩代码即可new webpack.optimize.UglifyJsPlugin()
HappyPack(webpack4后不再维护,使用thread-loader替代,见“vue简结”-“注意或优化的地方”-“webpack(vue.config.js)”-“parallel”)
由于运行在 Node.js 之上的 Webpack 是单线程模型的,所以Webpack 需要处理的事情需要一件一件的做,不能多件事一起做。我们需要Webpack 能同一时间处理多个任务,发挥多核 CPU 电脑的威力,HappyPack 就能让 Webpack 做到这点,它把任务分解给多个子进程去并发的执行,子进程处理完后再把结果发送给主进程,从而减少了总的构建时间。
- 样例
javascriptconst path = require('path'); const ExtractTextPlugin = require('extract-text-webpack-plugin'); const HappyPack = require('happypack'); module.exports = { module: { rules: [ { test: /\.js$/, // 把对 .js 文件的处理转交给 id 为 babel 的 HappyPack 实例 use: [[happypack/loader?id=babel'], // 排除 node_modules 目录下的文件,node_modules 目录下的文件都是采用的 ES5 语法,没必要再通过 Babel 去转换 exclude: path.resolve(__dirname, 'node_modules'), }, { // 把对 .css 文件的处理转交给 id 为 css 的 HappyPack 实例 test: /\.css$/, use: ExtractTextPlugin.extract({ use: [[happypack/loader?id=css'], }), } ] }, plugins: [ new HappyPack({ // 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件 id: 'babel', // 如何处理 .js 文件,用法和 Loader 配置中一样 loaders: [[babel-loader?cacheDirectory'], // ... 其它配置项 }), new HappyPack({ id: 'css', // 如何处理 .css 文件,用法和 Loader 配置中一样 loaders: [[css-loader'], }), new ExtractTextPlugin({ filename: `[name].css`, }), ], };注意
在 Loader 配置中,所有文件的处理都交给了 happypack/loader 去处理,使用紧跟其后的 querystring ?id=babel 去告诉 happypack/loader 去选择哪个 HappyPack 实例去处理文件。
在 Plugin 配置中,新增了两个 HappyPack 实例分别用于告诉 happypack/loader 去如何处理 .js 和 .css 文件。选项中的 id 属性的值和上面 querystring 中的 ?id=babel 相对应,选项中的 loaders 属性和 Loader 配置中一样。
参数
- id: String 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件
- loaders: Array 用法和 webpack Loader 配置中一样
- threads: Number 代表开启几个子进程去处理这一类型的文件,默认是3个,类型必须是整数
- verbose: Boolean 是否允许 HappyPack 输出日志,默认是 true
- threadPool: HappyThreadPool 代表共享进程池,即多个 HappyPack 实例都使用同一个共享进程池中的子进程去处理任务,以防止资源占用过多
- verboseWhenProfiling: Boolean 开启webpack --profile ,仍然希望HappyPack产生输出
- debug: Boolean 启用debug 用于故障排查。默认 false
DllPlugin和DllReferencePlugin
每当修改了业务代码之后,一些第三方的,体积比较大的模块(比如 vue、echarts、axios等)也会被重新打包,极大的浪费了时间。这时我们就可以使用 DLL 预先把一些第三方模块提前打包,以后修改业务代码再构建时就不会构建这些模块了。
splitChunks
有些库包会比较大,如果一起打包的话会导致文件过大,所以应该利用浏览器的并发数,把大文件拆开来,webpack4主要使用的是splitChunks配置,用来抽取公共代码
vue配置见“vue简结”-“注意或优化的地方”-“webpack(vue.config.js)”-“splitChunks”
默认配置
javascript{ "chunks": "all",//all, async(相当于import异步拆分打包的内容), initial(entry的配置) 三选一, 插件作用的chunks范围 "minSize": 0,//最小尺寸 "misChunks": 1,//最小chunks "maxAsyncRequests": 1,//最大异步请求chunks "maxInitialRequests": 1,//最大初始化chunks "name": undefined,//split 的 chunks name "automaticNameDelimiter": "~",//如果不指定name,自动生成name的分隔符(‘runtime~[name]’) "filename": undefined, "cacheGroups": {}//缓存组 }webpack热更新原理
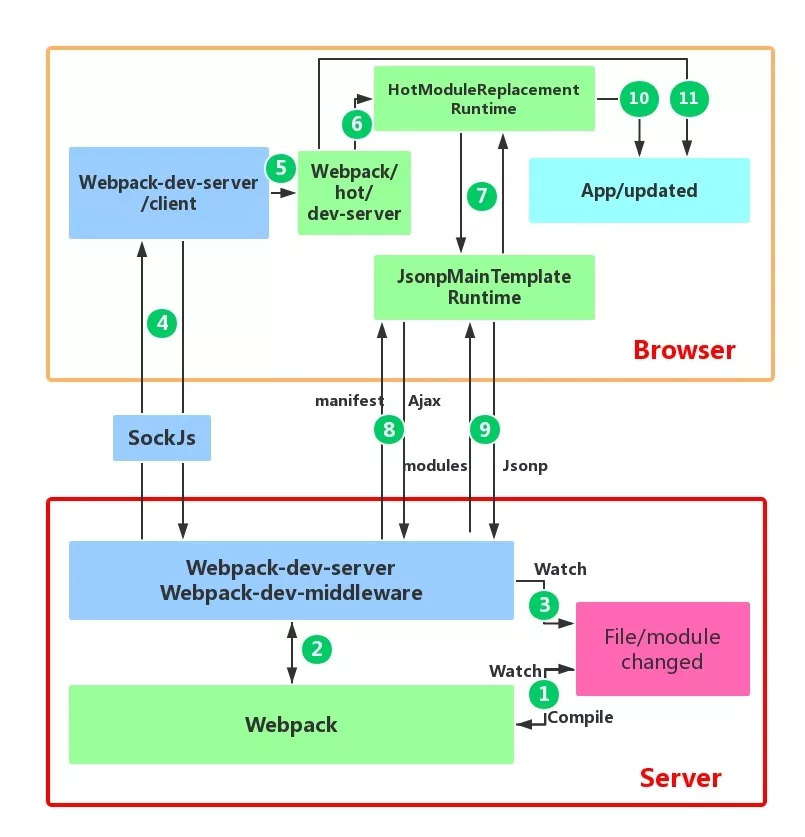
概念
webpack的热更新又称热替换(Hot Module Replacement),缩写为HMR。 这个机制可以做到不用刷新浏览器而将新变更的模块替换掉旧的模块。
流程
webpack监听文件变化,重新打包
在 webpack 的 watch 模式下,文件系统中某一个文件发生修改,webpack 监听到文件变化,根据配置文件对模块重新编译打包,并将打包后的代码通过简单的 JavaScript 对象保存在内存中。
webpack-dev-server中间件调用webpack的api将代码打包到内存
webpack-dev-server 和 webpack 之间的接口交互,而在这一步,主要是 dev-server 的中间件 webpack-dev-middleware 和 webpack 之间的交互,webpack-dev-middleware 调用 webpack 暴露的 API对代码变化进行监控,并且告诉 webpack,将代码打包到内存中。
webpack-dev-server监听配置文件夹中静态文件的变化,通知浏览器刷新
webpack-dev-server 对文件变化的一个监控,这一步不是监控代码变化重新打包。当在配置文件中配置了devServer.watchContentBase 为 true 的时候,Server 会监听这些配置文件夹中静态文件的变化,变化后会通知浏览器端对应用进行 live reload。注意,这儿是浏览器刷新,和 HMR 是两个概念。
webpack-dev-server建立浏览器端和服务端的websocket,浏览器根据传来的webpack打包信息、文件变化信息、新模块hash值,进行后续操作
也是 webpack-dev-server 代码的工作,该步骤主要是通过 sockjs(webpack-dev-server 的依赖)在浏览器端和服务端之间建立一个 websocket 长连接,将 webpack 编译打包的各个阶段的状态信息告知浏览器端,同时也包括第三步中 Server 监听静态文件变化的信息。浏览器端根据这些 socket 消息进行不同的操作。当然服务端传递的最主要信息还是新模块的 hash 值,后面的步骤根据这一 hash 值来进行模块热替换。
webpack根据传来的信息进行模块热更新
webpack-dev-server/client 端并不能够请求更新的代码,也不会执行热更模块操作,而把这些工作又交回给了 webpack,webpack/hot/dev-server 的工作就是根据 webpack-dev-server/client 传给它的信息以及 dev-server 的配置决定是刷新浏览器呢还是进行模块热更新。当然如果仅仅是刷新浏览器,也就没有后面那些步骤了。
HMR接收到之前的hash值,通过ajax拿到所有要更新模块的hash值列表,再通过jsonp获取最新代码
HotModuleReplacement.runtime 是客户端 HMR 的中枢,它接收到上一步传递给他的新模块的 hash 值,它通过 JsonpMainTemplate.runtime 向 server 端发送 Ajax 请求,服务端返回一个 json,该 json 包含了所有要更新的模块的 hash 值,获取到更新列表后,该模块再次通过 jsonp 请求,获取到最新的模块代码。这就是上图中 7、8、9 步骤。
Plugin进行模块新旧对比,包括更新模块的依赖项,决定更新的模块
决定 HMR 成功与否的关键步骤,在该步骤中,HotModulePlugin 将会对新旧模块进行对比,决定是否更新模块,在决定更新模块后,检查模块之间的依赖关系,更新模块的同时更新模块间的依赖引用。
HMR 失败,刷新浏览器
当 HMR 失败后,回退到 live reload 操作,也就是进行浏览器刷新来获取最新打包代码。
webpack热更新失效问题
路径设置正确,devServer开启了hot,plugin加了HMU,每次改变文件都能看到打印信息,但是页面没变。
原理:热更新对devServer端口内的内容有效,项目端口里的文件不生效
解决:配合使用htmlWebpackPlugin,自动生成html模板以便查看js和css路径是否正确,在项目端口页面引用devServer的js和css
javascriptconst path = require('path'); const root_path = path.resolve(__dirname); const HtmlWebpackPlugin = require('html-webpack-plugin'); const CleanWebpackPlugin = require('clean-webpack-plugin'); const ExtractTextPlugin = require('extract-text-webpack-plugin'); const webpack = require('webpack'); module.exports = { // mode: 'production', mode: "development", devServer: { contentBase: './', hot: true, port: 9000, open: true }, entry: { //配置多个入口文件打包成多个代码块 index: path.resolve(root_path, 'js/index.js') }, output: { filename: '[name].min.js', path: path.resolve(root_path, 'minjs') }, module: { rules: [ { test: /\.js$/, loader: 'babel-loader', exclude: path.resolve(root_path, 'node_modules'), include: root_path }, { test: /\.scss/, use: ExtractTextPlugin.extract({ fallback: 'style-loader', use: [[css-loader', 'sass-loader'] }) } ] }, watch: true, watchOptions: { poll: 1000, // 每秒询问多少次 aggregateTimeout: 500, //防抖 多少毫秒后再次触发 ignored: /node_modules/ //忽略时时监听 } plugins: [ new HtmlWebpackPlugin({ title: 'Hot Module Replacement' }), new webpack.NamedModulesPlugin(), new webpack.HotModuleReplacementPlugin(), new ExtractTextPlugin({ filename: 'mincss/[name].min.css', allChunks: true }) ] }js打包文件监听(热打包)
- watch(需刷新浏览器)
package.json
javascript{ // ... "scripts": { "test": "echo \"Error: no test specified\" && exit 1", "build": "webpack", "watch": "webpack --watch" // 新增配置 } // ... }- webpack-dev-server
package.json
javascript{ // ... "scripts": { "test": "echo \"Error: no test specified\" && exit 1", "build": "webpack", "dev": "webpack-dev-server --open" // 新增配置,运行 npm run dev 会自动打开浏览器 } // ... }webpack.config.js
javascript'use strict' const path = require('path'); var webpack = require('webpack'); // 引进 webpack module.exports = { // ... mode:'development', // production 改为开发环境,因为只有开发环境才用到热更新 module:{ // ... }, plugins:[ new webpack.HotModuleReplacementPlugin() ], devServer:{ contentBase:'./dist', hot: true } }webpack文件的构建
- entry: 入口文件
- resolve: 文件路径指向(可加快打包过程)
- output: 输出文件
- module: 在webpack中一个模块对应一个文件。webpack会从entry开始,递归找出所有依赖的模块
- rules
- test: 匹配的文件名正则
- use
- loader: 模块转换器,用于将模块的原内容按照需求转换成新内容
- option: 选项
- rules
- plugins: 拓展插件解决loader无法完成的事,如压缩
webpack执行
初始化参数
- 从配置文件(默认webpack.config.js)和shell语句中读取与合并参数,得出最终的参数
- 实例化Compiler
- 依次调用插件的apply方法,让插件可以监听后续的所有事件节点。同时向插件中传入compiler实例的引用,以方便插件通过compiler调用webpack的api
- 应用文件系统到compiler对象
- 读取配置的Entrys,为每个Entry实例化一个对应的EntryPlugin
- 调用完所有内置的和配置的插件的apply方法
- 根据配置初始化resolver,resolver负责在文件系统中寻找指定路径的文件
开始编译
用上一步得到的参数初始化Comiler对象,加载所有配置的插件,通过执行对象的run方法开始执行编译
确定入口
根据配置中的entry找出所有的入口文件
编译模块
- 启动一次编译
- 在监听模式下启动编译,文件发生变化会重新编译
- 告诉插件一次新的编译将要启动,同时会给插件带上compiler对象
- 检测到文件变化,便有一次新的compilation被创建,对象包含了当前的模块资源、编译生成资源、变化的文件等,提供事件回调给插件进行拓展
- 新的compilation对象创建完毕后,从entry开始读取文件,根据文件类型和编译的loader对文件进行编译,编译完后再找出该文件依赖的文件,递归地编译和解析
- 使用相应的Loader去转换一个模块
- 使用acorn解析转换后的内容,输出对应的抽象语法树
- 分析其AST,当遇到require等导入其他模块的语句时,便将其加入依赖的模块列表中,同时对于新找出来的模块递归分析,最终弄清楚所有模块的依赖关系
- 所有模块及依赖的模块都通过Loader转换完成,根据依赖关系生成Chunk
- 一次compilation执行完成
- 当遇到错误会触发改事件,该事件不会导致webpack退出
完成编译模块
经过第四步之后,得到了每个模块被翻译之后的最终内容以及他们之间的依赖关系
输出资源
- 所有需要输出的文件已经生成,询问插件有哪些文件需要输出,有哪些不需要输出
- 确定好要输出哪些文件后,执行文件输出
- 文件输出完毕
- 成功完成一次完整的编译和输出流程
- 如果在编译和输出中出现错误,导致webpack退出,就会直接跳转到本步骤,插件可以在本事件中获取具体的错误原因
输出完成
在确定好输出内容后,根据配置(webpack.config.js && shell)确定输出的路径和文件名,将文件的内容写入文件系统中(fs)
webpack会在特定的时间点广播特定的事件,插件监听事件并执行相应的逻辑,并且插件可以调用webpack提供的api改变webpack的运行结果
webpack编写plugins
新建项目
- npm init -y
- npm install webpack webpack-cli --save-dev
- 新建文件夹src,index.js
- index.js
javascriptconsole.log('hello world'); webpack.config.js- webpack.config.js
javascriptconst path = require('path'); module.exports = { mode: 'development', entry: { main: './src/index.js' }, output: { path: path.resolve(__dirname, 'dist'), filename: '[name].js' } }- package.json
javascript"scripts": { "debug": "node --inspect --inspect-brk node_modules/webpack/bin/webpack.js", "build": "webpack" }插件样例(dist下生成版权信息的js)
- 根目录下新建文件夹plugins
- 新建js叫copyright-webpack-plugin.jsjavascript
//loader是一个函数,插件是一个类 class CopyrightWebpackPlugin { constructor(){ console.log('插件被使用了') } //compiler是webpack的一个实例,这个实例存储了webpack各种信息,所有打包信息 //https://webpack.js.org/api/compiler-hooks //hooks是钩子,里面定义了时刻值 apply(compiler) { //用到了hooks,emit这个时刻,在输出资源之前,是一个异步函数 //compilation是这一次的打包信息,所以跟compiler是不一样的 //tapAsync接受两个参数,第一个是名字, compiler.hooks.emit.tapAsync('CopyrightWebpackPlugin',(compilation, cb)=>{ debugger; compilation.assets[[copyright.txt'] = { source: function(){ return 'copyright by q' }, size: function() { return 15 } }; // 最后一定要调用cb cb(); }) //同步的时刻,后面只要一个参数就可以了 compiler.hooks.compile.tap('CopyrightWebpackPlugin',(compilation) => { console.log('compiler'); }) } } module.exports = CopyrightWebpackPlugin; - 在webpack.config.js使用javascript
const CopyRightWebpackPlugin = require('./plugins/copyright-webpack-plugin'); module.exports = { plugins: [ //插件要new的原因 new CopyRightWebpackPlugin() ], }
webpack编写loader
开发前注意
单一职责
一个 loader 只做一件事
链式组合
一次干5件事的loader ,不如5个只能干一件事的loader
模块化
module.export=...
无状态
loader间保持独立
使用 Loader 实用工具
loader-utils、schema-utils
loader 的依赖
外部资源必须声明,并引入依赖
javascriptimport path from 'path'; export default function(source) { var callback = this.async(); var headerPath = path.resolve('header.js'); this.addDependency(headerPath); fs.readFile(headerPath, 'utf-8', function(err, header) { if(err) return callback(err); //这里的 callback 相当于异步版的 return callback(null, header + "\n" + source); }); };代码公用
共用代码提取到一个运行时文件里,然后通过 require 把它引进每个 loader
绝对路径
不要在 loader 模块里写绝对路径,当项目根路径变了,会干扰 webpack 计算 hash。loader-utils 里有一个 stringifyRequest 方法,它可以把绝对路径转化为相对路径。
同伴依赖
开发的 loader 只是简单包装另外一个包,应该在 package.json 中将这个包设为同伴依赖peerDependency。这可以让应用开发者知道该指定哪个具体的版本。
javascript"peerDependencies": { "node-sass": "^4.0.0" }
实践(html-minify-loader)
创建 loader 的 文件
src/loaders/html-minify-loader.js
配置 webpack.config.js
javascriptmodule: { rules: [{ test: /\.html$/, use: [[html-loader', 'html-minify-loader'] // 处理顺序 html-minify-loader => html-loader => webpack }] }, resolveLoader: { // 因为 html-loader 是开源 npm 包,所以这里要添加 'node_modules' 目录 modules: [path.join(__dirname, './src/loaders'), 'node_modules'] }示例 html 和 js 来测试
src/example.html
html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> </body> </html>src/app.js
javascriptvar html = require('./expamle.html'); console.log(html);处理 src/loaders/html-minify-loader.js
loader 是一个 node 模块,它导出一个函数,该函数的参数是 require 的源模块,处理 source 后把返回值交给下一个 loader
javascriptmodule.exports = function (source) { // 处理 source ... return handledSource; }或
javascriptmodule.exports = function (source) { // 处理 source ... this.callback(null, handledSource) return handledSource; }如果是处理顺序排在最后一个的 loader,那么它的返回值将最终交给 webpack 的 require,它一定是一个 node 模块的可执行的 JS 脚本。
javascript// 处理顺序排在最后的 loader module.exports = function (source) { // 这个 loader 的功能是把源模块转化为字符串交给 require 的调用方 return 'module.exports = ' + JSON.stringify(source); }使用 minimize 这个库来完成核心的压缩功能,loader-utils配置获取参数
javascriptvar Minimize = require('minimize'); var loaderUtils = require('loader-utils'); module.exports = function(source) { var callback = this.async();//loader 写成异步的方式,这样不会阻塞其他编译进度 if (this.cacheable) { this.cacheable(); } var opts = loaderUtils.getOptions(this) || {};//这里拿到 webpack.config.js 的 loader 配置 var minimize = new Minimize(opts); minimize.parse(source, callback); };webpack.config.js 中设置传入参数
javascriptmodule: { rules: [{ test: /\.html$/, use: [[html-loader', { loader: 'html-minify-loader', options: { comments: false } }] }] }, resolveLoader: { modules: [path.join(__dirname, './src/loaders'), 'node_modules'] }
webpack 编译 import
import moduleName from 'xxModule'和import('xxModule')经过webpack编译打包后最终变成了什么?在浏览器中是怎么运行的?
import经过webpack打包以后变成一些Map对象,key为模块路径,value为模块的可执行函数;
代码加载到浏览器以后从入口模块开始执行,其中执行的过程中,最重要的就是webpack定义的__webpack_require__函数,负责实际的模块加载并执行这些模块内容,返回执行结果,其实就是读取Map对象,然后执行相应的函数;
当然其中的异步方法(import('xxModule'))比较特殊一些,它会单独打成一个包,采用动态加载的方式,具体过程:当用户触发其加载的动作时,会动态的在head标签中创建一个script标签,然后发送一个http请求,加载模块,模块加载完成以后自动执行其中的代码,主要的工作有两个,更改缓存中模块的状态,另一个就是执行模块代码。
javascript(function (modules) { // 插入script,异步请求,chunkid等函数 })({ // src/index.js 模块 "./src/index.js": (function (module, __webpack_exports__, __webpack_require__) { "use strict"; __webpack_require__.r(__webpack_exports__); var _num_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/num.js"); Object(_num_js__WEBPACK_IMPORTED_MODULE_0__["print"])() function button() { const button = document.createElement('button') const text = document.createTextNode('click me') button.appendChild(text) button.onclick = e => __webpack_require__.e(0) .then(__webpack_require__.bind(null, "./src/info.js")) .then(res => { console.log(res.log) }) return button } document.body.appendChild(button()) //# sourceURL=webpack:///./src/index.js?"); }), // ./src/num.js 模块 "./src/num.js": (function (module, __webpack_exports__, __webpack_require__) { "use strict"; __webpack_require__.r(__webpack_exports__); __webpack_require__.d(__webpack_exports__, "print", function () { return print; }); var _tmp_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/tmp.js"); function print() { Object(_tmp_js__WEBPACK_IMPORTED_MODULE_0__["tmpPrint"])() console.log('我是 num.js 的 print 方法') } //# sourceURL=webpack:///./src/num.js?"); }) })完整:
javascript/** * modules = { * './src/index.js': function () {}, * './src/num.js': function () {}, * './src/tmp.js': function () {} * } */ (function (modules) { // webpackBootstrap /** * install a JSONP callback for chunk loading * 模块加载成功,更改缓存中的模块状态,并且执行模块内容 * @param {*} data = [ * [chunkId], * { * './src/info.js': function () {} * } * ] */ function webpackJsonpCallback(data) { var chunkIds = data[0]; var moreModules = data[1]; // add "moreModules" to the modules object, // then flag all "chunkIds" as loaded and fire callback var moduleId, chunkId, i = 0, resolves = []; for (; i < chunkIds.length; i++) { chunkId = chunkIds[i]; if (Object.prototype.hasOwnProperty.call(installedChunks, chunkId) && installedChunks[chunkId]) { resolves.push(installedChunks[chunkId][0]); } // 这里将模块的加载状态改为了 0,表示加载完成 installedChunks[chunkId] = 0; } for (moduleId in moreModules) { if (Object.prototype.hasOwnProperty.call(moreModules, moduleId)) { // 执行模块代码 modules[moduleId] = moreModules[moduleId]; } } if (parentJsonpFunction) parentJsonpFunction(data); while (resolves.length) { resolves.shift()(); } }; // The module cache, 模块缓存,类似于 commonJS 的 require 缓存机制,只不过这里的 key 是相对路径 var installedModules = {}; /** * 定义 chunk 的加载情况,比如 main = 0 是已加载 * object to store loaded and loading chunks * undefined = chunk not loaded * null = chunk preloaded/prefetched * Promise = chunk loading * 0 = chunk loaded */ var installedChunks = { "main": 0 }; // script path function, 返回需要动态加载的 chunk 的路径 function jsonpScriptSrc(chunkId) { return __webpack_require__.p + "" + chunkId + ".main.js" } /** * The require function * 接收一个 moduleId,其实就是一个模块相对路径,然后查缓存(没有则添加缓存), * 然后执行模块代码,返回模块运行后的 module.exports * 一句话总结就是 加载指定模块然后执行,返回执行结果(module.exports) * * __webpack_require__(__webpack_require__.s = "./src/index.js") */ function __webpack_require__(moduleId) { // Check if module is in cache if (installedModules[moduleId]) { return installedModules[moduleId].exports; } /** * Create a new module (and put it into the cache) * * // 示例 * module = installedModules[[./src/index.js'] = { * i: './src/index.js', * l: false, * exports: {} * } */ var module = installedModules[moduleId] = { i: moduleId, l: false, exports: {} }; /** * Execute the module function * modules[[./src/index.js'] is a function */ modules[moduleId].call(module.exports, module, module.exports, __webpack_require__); // Flag the module as loaded module.l = true; // Return the exports of the module return module.exports; } // This file contains only the entry chunk. // The chunk loading function for additional chunks /** * */ __webpack_require__.e = function requireEnsure(chunkId) { var promises = []; // JSONP chunk loading for javascript // 从缓存中找该模块 var installedChunkData = installedChunks[chunkId]; // 0 means "already installed". if (installedChunkData !== 0) { // 说明模块没有安装 // a Promise means "currently loading". if (installedChunkData) { promises.push(installedChunkData[2]); } else { // setup Promise in chunk cache var promise = new Promise(function (resolve, reject) { installedChunkData = installedChunks[chunkId] = [resolve, reject]; }); promises.push(installedChunkData[2] = promise); // start chunk loading, create script element var script = document.createElement('script'); var onScriptComplete; script.charset = 'utf-8'; // 设置超时时间 script.timeout = 120; if (__webpack_require__.nc) { script.setAttribute("nonce", __webpack_require__.nc); } // script.src = __webpack_public_path__ + chunkId + main.js, 即模块路径 script.src = jsonpScriptSrc(chunkId); // create error before stack unwound to get useful stacktrace later var error = new Error(); // 加载结果处理函数 onScriptComplete = function (event) { // avoid mem leaks in IE. script.onerror = script.onload = null; clearTimeout(timeout); var chunk = installedChunks[chunkId]; if (chunk !== 0) { // chunk 状态不为 0 ,说明加载出问题了 if (chunk) { var errorType = event && (event.type === 'load' ? 'missing' : event.type); var realSrc = event && event.target && event.target.src; error.message = 'Loading chunk ' + chunkId + ' failed.\n(' + errorType + ': ' + realSrc + ')'; error.name = 'ChunkLoadError'; error.type = errorType; error.request = realSrc; chunk[1](error); } installedChunks[chunkId] = undefined; } }; // 超时定时器,超时以后执行 var timeout = setTimeout(function () { onScriptComplete({ type: 'timeout', target: script }); }, 120000); // 加载出错或者加载成功的处理函数 script.onerror = script.onload = onScriptComplete; // 将 script 标签添加到 head 标签尾部 document.head.appendChild(script); } } return Promise.all(promises); }; // expose the modules object (__webpack_modules__) __webpack_require__.m = modules; // expose the module cache __webpack_require__.c = installedModules; /** * define getter function for harmony exports * @param {*} exports = {} * @param {*} name = 模块名 * @param {*} getter => 模块函数 * * 在 exports 对象上定义一个 key value,key 为模块名称,value 为模块的可执行函数 * exports = { * moduleName: module function * } */ __webpack_require__.d = function (exports, name, getter) { if (!__webpack_require__.o(exports, name)) { Object.defineProperty(exports, name, { enumerable: true, get: getter }); } }; /** * define __esModule on exports * @param {*} exports = {} * * exports = { * __esModule: true * } */ __webpack_require__.r = function (exports) { if (typeof Symbol !== 'undefined' && Symbol.toStringTag) { Object.defineProperty(exports, Symbol.toStringTag, { value: 'Module' }); } Object.defineProperty(exports, '__esModule', { value: true }); }; // create a fake namespace object // mode & 1: value is a module id, require it // mode & 2: merge all properties of value into the ns // mode & 4: return value when already ns object // mode & 8|1: behave like require __webpack_require__.t = function (value, mode) { if (mode & 1) value = __webpack_require__(value); if (mode & 8) return value; if ((mode & 4) && typeof value === 'object' && value && value.__esModule) return value; var ns = Object.create(null); __webpack_require__.r(ns); Object.defineProperty(ns, 'default', { enumerable: true, value: value }); if (mode & 2 && typeof value != 'string') for (var key in value) __webpack_require__.d(ns, key, function (key) { return value[key]; }.bind(null, key)); return ns; }; // getDefaultExport function for compatibility with non-harmony modules __webpack_require__.n = function (module) { var getter = module && module.__esModule ? function getDefault() { return module[[default']; } : function getModuleExports() { return module; }; __webpack_require__.d(getter, 'a', getter); return getter; }; // Object.prototype.hasOwnProperty.call __webpack_require__.o = function (object, property) { return Object.prototype.hasOwnProperty.call(object, property); }; // __webpack_public_path__ __webpack_require__.p = ""; // on error function for async loading __webpack_require__.oe = function (err) { console.error(err); throw err; }; /** * 通过全局属性存储异步加载的资源项,打包文件首次加载时如果属性值不为空,则说明已经有资源被加载了, * 将这些资源同步到installedChunks对象中,避免资源重复加载,当然也是这句导致微应用框架single-spa中的所有子应用导出的 * 包名需要唯一,否则一旦异步的重名模块存在,重名的后续模块不会被加载,且显示的资源是第一个加载的重名模块, * 也就是所谓的JS全局作用域的污染 * * 其实上面说的这个问题,webpack官网已经提到了 * https://webpack.docschina.org/configuration/output/#outputjsonpfunction */ var jsonpArray = window["webpackJsonp"] = window["webpackJsonp"] || []; var oldJsonpFunction = jsonpArray.push.bind(jsonpArray); jsonpArray.push = webpackJsonpCallback; jsonpArray = jsonpArray.slice(); for (var i = 0; i < jsonpArray.length; i++) webpackJsonpCallback(jsonpArray[i]); var parentJsonpFunction = oldJsonpFunction; /** * 入口位置 * Load entry module and return exports */ return __webpack_require__(__webpack_require__.s = "./src/index.js"); }) ({ // 代码中所有的 import moduleName from 'xxModule' 变成了以下的 Map 对象 // /src/index.js 模块 "./src/index.js": /** * @param module = { * i: './src/index.js', * l: false, * exports: {} * * @param __webpack_exports__ = module.exports = {} * * @param __webpack_require__ => 自定义的 require 函数,加载指定模块,并执行模块代码,返回执行结果 * */ (function (module, __webpack_exports__, __webpack_require__) { "use strict"; /** * * define __esModule on exports * __webpack_exports = module.exports = { * __esModule: true * } */ __webpack_require__.r(__webpack_exports__); // 加载 ./src/num.js 模块 var _num_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/num.js"); Object(_num_js__WEBPACK_IMPORTED_MODULE_0__["print"])() function button() { const button = document.createElement('button') const text = document.createTextNode('click me') button.appendChild(text) /** * 异步执行部分 */ button.onclick = e => __webpack_require__.e(0) // 模块异步加载完成后,开始执行模块内容 => window["webpackJsonp"].push = window["webpackJsonp"].push = function (data) {} .then(__webpack_require__.bind(null, "./src/info.js")) .then(res => { console.log(res.log) }) return button } document.body.appendChild(button()) //# sourceURL=webpack:///./src/index.js?"); }), // /src/num.js 模块 "./src/num.js": /** * @param module = { * i: './src/num.js', * l: false, * exports: {} * * @param __webpack_exports__ = module.exports = {} * * @param __webpack_require__ => 自定义的 require 函数,加载指定模块,并执行模块代码,返回执行结果 * */ (function (module, __webpack_exports__, __webpack_require__) { "use strict"; /** * * define __esModule on exports * __webpack_exports = module.exports = { * __esModule: true * } */ __webpack_require__.r(__webpack_exports__); /** * module.exports = { * __esModule: true, * print * } */ __webpack_require__.d(__webpack_exports__, "print", function () { return print; }); // 加载 ./src/tmp.js 模块 var _tmp_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/tmp.js"); function print() { Object(_tmp_js__WEBPACK_IMPORTED_MODULE_0__["tmpPrint"])() console.log('我是 num.js 的 print 方法') } //# sourceURL=webpack:///./src/num.js?"); }), // /src/tmp.js 模块 "./src/tmp.js": /** * @param module = { * i: './src/num.js', * l: false, * exports: {} * * @param __webpack_exports__ = module.exports = {} * * @param __webpack_require__ => 自定义的 require 函数,加载指定模块,并执行模块代码,返回执行结果 * */ (function (module, __webpack_exports__, __webpack_require__) { "use strict"; /** * * define __esModule on exports * __webpack_exports = module.exports = { * __esModule: true * } */ __webpack_require__.r(__webpack_exports__); /** * module.exports = { * __esModule: true, * tmpPrint * } */ __webpack_require__.d(__webpack_exports__, "tmpPrint", function () { return tmpPrint; }); function tmpPrint() { console.log('tmp.js print') } //# sourceURL=webpack:///./src/tmp.js?"); }) });
vite
- 参考链接:
- 详解:
概念
什么是vite
Vite 是一个由原生 ES Module 驱动的 Web 开发构建工具。在开发环境下基于浏览器原生 ES imports 开发,在生产环境下基于 Rollup 打包。
为什么要使用Vite(解决的问题)
解决开发环境启动和热更新慢的问题。
使用JS开发的工具通常需要很长的时间才能启动开发服务器,且这个启动时间与代码量、代码复杂度正相关。即使使用HMR,文件修改后的效果也要几秒钟才能在浏览器中反应出来,代表如Webpack。
针对开发环境中的启动慢问题,Vite开发环境冷启动无需打包,无需分析模块之间的依赖,同时也无需在启动开发服务器前进行编译,启动时还会使用esbuild来进行预构建。
而Webpack 启动后会做一堆事情,经历一条很长的编译打包链条,从入口开始需要逐步经历语法解析、依赖收集、代码转译、打包合并、代码优化,最终将高版本的、离散的源码编译打包成低版本、高兼容性的产物代码,在 Node 运行时下性能必然是有问题。
vite特点
- Lightning fast cold server start - 闪电般的冷启动速度
- Instant hot module replacement (HMR) - 即时热模块更换(热更新)
- True on-demand compilation - 真正的按需编译
浏览器兼容性
Chrome63+
主流构建工具对比
构建工具指能自动对代码执行检验、转换、压缩等功能的工具。常见功能包括:代码转换、代码打包、代码压缩、HMR、代码检验。
Browserify
- 预编译模块化方案(文件打包工具)
- Browserify基于流方式干净灵活
- 遵循commonJS规范打包JS
- 可引入插件打包CSS等其他资源(非原生能力)
Gulp
- 基于流的自动化构建工具(工程化)
- 配置复杂度高,偏向编程式,需要定义task处理构建
- 支持监听读写文件
- 可搭配Browserify等模块化工具来使用
Parcel
- 极速打包(工程化:极速0配置)
- 零配置,但造成了配置不灵活,内置常见场景的构建方案及其依赖,无需再次安装(babel等)
- 以html入口,自动检测和打包依赖
- 不支持SourceMap
- 无法Tree-shaking
Webpack
- 预编译模块化方案(工程化:大而全)
- 通过配置文件达到一站式配置
- loader进行资源转换,功能全面(css+js+icon+front)
- 插件丰富,灵活扩展
- 社群庞大
- 大型项目构建慢
Rollup
- 基于ES6打包(模块打包工具)
- Tree-shaking
- 打包文件小且干净,执行效率更高
- 更专注于JS打包
Snowpack
- 基于ESM运行时编译(工程化:ESM运行时)
- 无需递归循环依赖组装依赖树
- 默认输出单独的构建模块(未打包),可选择不同打包器(webpack、rollup等)
Vite
- 基于ESM运行时打包
- 借鉴了Snowpack
- 生产环境使用Rollup,集成度更高,相比Snowpack支持多页面、库模式、动态导入自动polyfill等
vite与webpack对比
webpack打包过程
- 识别入口文件
- 通过逐层识别模块依赖。(Commonjs、amd或者es6的import,webpack都会对其进行分析。来获取代码的依赖)
- webpack做的就是分析代码。转换代码,编译代码,输出代码
- 最终形成打包后的代码
webpack打包原理
- 先逐级递归识别依赖,构建依赖图谱
- 将代码转化成AST抽象语法树
- 在AST阶段中去处理代码
- 把AST抽象语法树变成浏览器可以识别的代码,然后输出
vite打包原理
- 声明一个入口 script 标签类型为 module (main.js),通过get请求获取内容
- 扫描文件内容,遇到import,则get请求获取内容,递归进行
- 简单合并和整合文件,不打包编译
webpack缺点改进
- 缓慢的服务器启动
Vite 通过在一开始将应用中的模块区分为 依赖 和 源码 两类,改进了开发服务器启动时间。
依赖
大多为纯 JavaScript 并在开发时不会变动。一些较大的依赖(例如有上百个模块的组件库)处理的代价也很高。依赖也通常会以某些方式(例如 ESM 或者 CommonJS)被拆分到大量小模块中。
Vite 将会使用 esbuild 预构建依赖。Esbuild 使用 Go 编写,并且比以 JavaScript 编写的打包器预构建依赖快 10-100 倍。
源码
通常包含一些并非直接是 JavaScript 的文件,需要转换(例如 JSX,CSS 或者 Vue/Svelte 组件),时常会被编辑。同时,并不是所有的源码都需要同时被加载。(例如基于路由拆分的代码模块)。
Vite 以 原生 ES Module 方式服务源码。这实际上是让浏览器接管了打包程序的部分工作:Vite 只需要在浏览器请求源码时进行转换并按需提供源码。根据情景动态导入的代码,即只在当前屏幕上实际使用时才会被处理。
- 热更新效率低下
webpack编辑文件后将重新构建文件本身。Vite 只需要精确地使已编辑的模块与其最近的 HMR 边界之间的链失效(大多数时候只需要模块本身),使 HMR 更新始终快速,无论应用的大小。
Vite 同时利用 HTTP 头来加速整个页面的重新加载(再次让浏览器为我们做更多事情):源码模块的请求会根据 304 Not Modified 进行协商缓存,而依赖模块请求则会通过 Cache-Control: max-age=31536000,immutable 进行强缓存,因此一旦被缓存它们将不需要再次请求。
vite缺点
- 生态不如webpack
- prod环境的构建,目前用的Rollup,esbuild对于css和代码分割不是很友好
- 要求较高版本的浏览器兼容ES Module
vite实现
- 请求拦截
启动一个 koa 服务器拦截浏览器ES Module的请求,通过 path 找到目录下对应的文件做一定的处理最终以 ES Modules 格式返回给客户端
Vite使用了 esbuild,支持如babel, 压缩等的功能。esbuild 是一个全新的js打包工具,使用了 go 作为底层语言,静态语言会比 动态语言 快很多。
node_modules 模块的处理
浏览器只能通过相对路径去寻找import的文件,Vite对其做了一些特殊处理,若 path 的请求路径满足 /^/@modules// 格式时,被认为是一个 node_modules 模块。
如何将代码中的 /文件 转化为 /@modules/文件?
ES Module Lexer会返回js文件中导入的模块并以数组形式返回。Vite 通过该数组判断是否为一个 node_modules 模块。若是则进行对应重写。
通过 /@modules/文件 在 node_modules 文件下找到对应模块
浏览器发送 path 为 /@modules/:id 的对应请求后。会被 Vite 客户端做一层拦截,最终找到对应的模块代码进行返回。
.vue 文件的处理
拆分成 template , css ,script 模块三个模块进行分别处理。最后会对 script ,template, css 发送多个请求获取。
App.vue 获取script , App.vue?type=template 获取 template , App.vue?type=style 获取 style。这些代码都被插入在app.vue 返回的代码中。
静态资源(statics & asset & JSON )的加载
当请求的路径符合 image, media , fonts 或 JSON 格式,会被认为是一个静态资源。静态资源将处理成 ES Module 模块返回。
js/ts处理
esbuild转换ts到js对于类型操作仅仅是擦除,所以完全保证不了类型正确,因此需要额外校验类型,比如使用tsc --noEmit。
将ts转换成js后,浏览器便可以利用ESM直接拿到js资源。
- 热更新(Hot Module Reload)原理
在客户端与服务端建立了一个 websocket 链接,当代码被修改时,服务端发送消息通知客户端去请求修改模块的代码,完成热更新。
服务端原理
服务端做的就是监听代码文件的改变,在合适的时机向客户端发送 websocket 信息通知客户端去请求新的模块代码。
客户端原理
Vite的 websocket 相关代码在 处理 html 中时被写入代码中。
Vite 会接受到来自客户端的消息。通过不同的消息触发一些事件。做到浏览器端的即时热模块更换(热更新)。包括 connect、vue-reload、vue-rerender 等事件,分别触发组件vue 的重新加载,render等。
vite的一些问题
如果组件嵌套层级比较深,会影响速度吗?
可以看到请求 lodash 时 651 个请求只耗时 1.53s。这个耗时是完全可以接受的。
Vite 是完全按需加载的,在页面初始化时只会请求初始化页面的一些组件。(使用一些如 dynamic import 的优化)
ES module 是有一些优化的,浏览器会给请求的模块做一次缓存。当请求路径完全相同时,浏览器会使用浏览器缓存的代码。
Vite 只是一个用于开发环境的工具,上线仍会打包成一个 commonJs 文件进行调用。
浏览器性能数据
参考链接:
sendBeacon使用application/x-www-form-urlencoded发送数据
Chrome Performance常见名词解释(FP, FCP, LCP, DCL, FMP, TTI, TBT, FID, CLS)
详解:
- Window.performance
javascriptmemory: MemoryInfo; jsHeapSizeLimit: 2197815296; totalJSHeapSize: 15563541; usedJSHeapSize: 12592021; __proto__: MemoryInfo; navigation: PerformanceNavigation; //网页导航的类型 redirectCount: 0; type: 1; __proto__: PerformanceNavigation; onresourcetimingbufferfull: null; timeOrigin: 1571303991051.22; timing: PerformanceTiming; //包含延迟相关的性能信息 connectEnd: 1571303991051; connectStart: 1571303991051; domComplete: 1571303992579; domContentLoadedEventEnd: 1571303992574; domContentLoadedEventStart: 1571303992569; domInteractive: 1571303992569; domLoading: 1571303992522; domainLookupEnd: 1571303991051; domainLookupStart: 1571303991051; fetchStart: 1571303991051; loadEventEnd: 1571303992582; loadEventStart: 1571303992579; navigationStart: 1571303991049; redirectEnd: 0; redirectStart: 0; requestStart: 1571303991068; responseEnd: 1571303992519; responseStart: 1571303992515; secureConnectionStart: 0; unloadEventEnd: 1571303992518; unloadEventStart: 1571303992518; __proto__: PerformanceTiming; __proto__: Performance; //方法 performance.mark(time); //某一时刻,单位:ms,最高精确到5us performance.now(); //从某一时刻到调用该方法时刻的毫秒数 //页面加载时间 var perfData = window.performance.timing; var pageLoadTime = perfData.loadEventEnd - perfData.navigationStart; //请求响应时间 var connectTime = perfData.responseEnd - perfData.requestStart; //页面渲染时间 var renderTime = perfData.domComplete - perfData.domLoading;指标
FP(First Paint)首次绘制
是时间线上的第一个时间点,它代表网页的第一个像素渲染到屏幕上所用时间,也就是页面在屏幕上首次发生视觉变化的时间。
javascript//performance.getEntriesByType('paint’),取第一个时间 function getFPTime() { const timings = performance.getEntriesByType("paint")[0]; return timings ? Math.round(timings.startTime) : null; }FCP(First Contentful Paint)首次内容绘制
只有首次绘制文本、图片(包含背景图)、非白色的 canvas 或 SVG 时才被算作 FCP
javascript//2种方法 const domEntries = [] //1. 通过Mutation Observer观察到首次节点变动的时间 const observer = new MutationObserver((mutationsList)=>{ for(var mutation of mutationsList) { if (mutation.type == 'childList') { console.log('A child node has been added or removed.'); } if (mutation.type == 'addedNodes') { //TODO新增了节点,做处理,计算此时的可见性/位置/出现时间等信息,然后 push 进数组 ... domEntries.push(mutation) } } }); //2. 通过performance.getEntriesByType('paint’),取第二个时间 function getFPTime(){ const timings = performance.getEntriesByType('paint'); if(timings.length > 1)return timings[1] return timings ? Math.round(timings.startTime) : null //伪代码,算 DOM 变化时的最小那个时间,即节点首次变动的时间 return Math.round(domEntries.length ? Math.min(...domEntries.map(entry => entry.time)) : 0); }注意:
- FP 是当浏览器开始绘制内容到屏幕上
- FCP 是浏览器首次绘制来自 DOM 的内容
- FP 和 FCP 可能是相同的时间,也可能是先 FP 后 FCP。
FMP(First Meaningful Paint)首次有意义的绘制
页面主要内容出现在屏幕上的时间, 这是用户感知加载体验的主要指标。
白屏时间
白屏时间 = 地址栏输入网址后回车 - 浏览器出现第一个元素
通常认为浏览器开始渲染<body>或者解析完<head>的时间是白屏结束的时间点
从 head 的 title 后打印开始时间,从 head 末尾打印结束时间
首屏时间
首屏时间 = 地址栏输入网址后回车 - 浏览器第一屏渲染完成
从 head 的 title 后打印开始时间,从 body 末尾打印结束时间
w3c 标准(SPA 兴起后失效(peformance 与截屏计时工具不一致),现坐等 w3c 标准化)
javascriptvar perfData = window.performance.timing; var renderTime = perfData.domComplete - perfData.domLoading;找出加载最慢的图片
从 head 的 title 后打印开始时间,每个 img 的 onload 方法打印时间
FID(irst Input Delay)首次输入延迟
测量用户首次与您的站点交互时的时间(即当他们单击链接/点击按钮/使用自定义的 JavaScript 驱动控件时)到浏览器实际能够回应这种互动的时间
javascript// 方式一 function getFIDTime() { const timings = performance.getEntriesByType("first-input")[0]; return timings ? timings : null; } // 方式二,以下代码仅代表思路 ["click", "touch", "keydown"].forEach((eventType) => { window.addEventListener(eventType, eventHandle); }); function eventHandle(e) { const eventTime = e.timeStamp; //window.requestIdleCallback()方法将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应。函数一般会按先进先调用的顺序执行,然而,如果回调函数指定了执行超时时间timeout,则有可能为了在超时前执行函数而打乱执行顺序。 window.requestIdleCallback(onIdleCallback.bind(this, eventTime, e)); } function onIdleCallback(eventTime, e) { const now = window.performance.now(); const duration = now - eventTime; return { duration: Math.round(duration), timestamp: Math.round(eventTime), }[("click", "touch", "keydown")].forEach((eventType) => { window.removeEventListener(eventType, eventHandle); }); }TTI(Time To Interactive)可交互时间
应用在视觉上都已渲染出了,完全可以响应用户的输入了。是衡量应用加载所需时间并能够快速响应用户交互的指标
javascript//统计方式一:谷歌实验室写的npm包,tti-polyfill import ttiPolyfill from "tti-polyfill"; ttiPolyfill.getFirstConsistentlyInteractive().then((tti) => { ga("send", "event", { eventCategory: "Performance Metrics", eventAction: "TTI", eventValue: tti, nonInteraction: true, }); }); //统计方式二:在页面加载的一定时间内(如前50s内),以(domContentLoadedEventStart-navigationStart)+5为起始点,循环寻找,找到一个5s的窗口,其中网络请求不超过2个且没有长任务(>50ms),再找到该5秒窗口之前的最后一个长任务,该长任务结束的时间点就是可稳定交互时间。其中长任务可自定义时间或通过performance.getEntriesByType('long-task')获取 // 以下代码仅代表思路 const basicTime = 5000; function getTTITime( startTime, longTaskEntries, resourceEntries, domContentLoadedTime ) { let busyNetworkInWindow = []; let tti = startTime; while (startTime + basicTime <= 50000) { //从前50s 中去找 tti = startTime; longTasksInWindow = longTaskEntries.filter((task) => { return ( task.startTime < startTime + basicTime && task.startTime + task.duration > startTime ); }); if (longTasksInWindow.length) { const lastLongTask = longTasksInWindow[longTasksInWindow.length - 1]; startTime = lastLongTask.startTime + lastLongTask.duration; continue; } busyNetworkInWindow = resourceEntries.filter((request) => { return !( request.startTime >= startTime + basicTime || request.startTime + request.duration <= startTime ); }); if (busyNetworkInWindow.length > 2) { const firstRequest = busyNetworkInWindow[0]; startTime = firstRequest.startTime + firstRequest.duration; continue; } return Math.max(tti, domContentLoadedTime); } return Math.max(tti, domContentLoadedTime); }FCI(First CPU Idle)首次 CPU 空闲时间
一个网页已经满足了最小程度的与用户发生交互行为的时刻。当我们打开一个网页,我们并不需要等到一个网页完全加载好了,每一个元素都已经完成了渲染,然后再去与网页进行交互行为。网页满足了我们基本的交互的时间点是衡量网页性能的一个重要指标。
FCI 为在 FMP 之后,首次在一定窗口时间内没有长任务发生的那一时刻,并且如果这个时间点早于 DOMContentLoaded 时间,那么 FCI 的时间为 DOMContentLoaded 时间,窗口时间的计算函数可以根据 Lighthouse 提供的计算公式 N = f(t) = 4 _ e^(-0.045 _ t) + 1 进行自定义设计
FPS(Frames Per Second)每秒帧率
每秒钟画面更新次数,当今大多数设备的屏幕刷新率都是 60 次/秒
参考标准:
- 帧率能够达到 50 ~ 60 FPS 的动画将会相当流畅,让人倍感舒适;
- 帧率在 30 ~ 50 FPS 之间的动画,因各人敏感程度不同,舒适度因人而异;
- 帧率在 30 FPS 以下的动画,让人感觉到明显的卡顿和不适感;
- 帧率波动很大的动画,亦会使人感觉到卡顿
统计逻辑
利用 requestAnimationFrame,循环调用,当 now 大于 lastTime+1S 时,计算 FPS。若小于某个阀值则可以认为当前帧率较差,若连续小于多个阀值,则停止统计,当前页面处于卡顿状态,进入卡顿处理逻辑
LCP (Largest Contentful Paint) 最大内容渲染
代表在viewport中最大的页面元素加载的时间. LCP的数据会通过PerformanceEntry对象记录, 每次出现更大的内容渲染, 则会产生一个新的PerformanceEntry对象.(2019年11月新增)
DCL (DomContentloaded)
当 HTML 文档被完全加载和解析完成之后,DOMContentLoaded 事件被触发,无需等待样式表、图像和子框架的完成加载.
TBT (Total Blocking Time) 页面阻塞总时长
TBT汇总所有加载过程中阻塞用户操作的时长,在FCP和TTI之间任何long task中阻塞部分都会被汇总.
在主线程上运行任务所花费的总时间为560毫秒,但只有345(200 + 40 + 105)毫秒的时间被视为阻塞时间(超过50ms的Task都会被记录)
- CLS (Cumulative Layout Shift) 累积布局偏移
一个元素初始时和其hidden之间的任何时间如果元素偏移了, 则会被计算进去, 具体的计算方法可看这篇文章 https://web.dev/cls/
- 设备信息
- 用户设备:window.navigator.userAgent
- 设备网络:window.navigator.connection
- 设备像素比:window.devicePixelRatio
- 上报策略
- pv/uv:监听各种页面切换的情况;SPA 页面,可以监听 hashChange
- 性能数据/设备信息/网络状况
- 在页面离开前上报,beforeUnload/visibilitychange/pagehide…+sendBeancon/Ajax
- img 标签+切片+压缩
获取特定性能数据(getEntriesByType() 和 getEntriesByName())
javascriptperformance.getEntriesByType("paint"); performance.getEntriesByName( "https://www.google.com/images/nav_logo299.webp" ); //Interface-------------------EntryType---Name-----InitiatorType (发起请求的类型) //PerformanceResourceTiming---resource----资源 URL--link、img、script、css、fetch、beacon、iframe、other //PerformanceNavigationTiming-navigation--页面 URL--navigation //PerformancePaintTiming------paint-------first-paint、first-contentful-paint---/ //PerformanceEventTiming------first-input-keydown---/ //PerformanceMark-------------mark--------mark 被创建时给出的 name---/ //PerformanceMeasure----------measure-----measure 被创建时给出的 name---/ //PerformanceLongTaskTiming---longtask----/---------/Resource Hints - 加载性能
资源提示: dns-prefetch(Resource Hints: dns-prefetch)
给浏览器提示,在后台执行 DNS 查找以提高性能。
html<link rel="dns-prefetch" href="//example.com" />资源提示:预连接(Resource Hints: preconnect)
给浏览器提示在后台开始连接握手(DNS,TCP,TLS)以提高性能。
html<link rel="preconnect" href="//example.com" /> <link rel="preconnect" href="//cdn.example.com" crossorigin />资源提示:预取(Resource Hints: prefetch)
告诉浏览器获取下一次导航可能需要的资源。大多数情况下,这意味着将以极低的优先级来获取资源
html<link rel="prefetch" href="//example.com/next-page.html" as="document" crossorigin="use-credentials" /> <link rel="prefetch" href="/library.js" as="script" />- 用户代理在获取资源后不会做预处理,也不会在当前页面使用这个资源。
- as 属性是一个可选属性,符合 [PRELOAD] 中的定义。
- crossorigin CORS 设置属性是一个可选属性,指示指定资源的 CORS 策略。
资源提示:预渲染(Resource Hints: prerender)
给浏览器提供提示,以便在后台呈现指定的页面,如果用户导航到页面,则会加快页面加载速度。用于获取下一个可能的 HTML 导航,并通过获取必要的子资源并执行它们来预处理 HTML 响应
html<link rel="prerender" href="//example.com/next-page.html" />
Preload - 加载性能
应用程序可以使用 preload 关键字启动 CSS 资源的早期、高优先级和非呈现阻塞获取,然后应用程序可以在适当的时间应用这些获取
html<link rel="preload" href="/styles/other.css" as="style" />Page Visibility - 节省资源
javascriptvar videoElement = document.getElementById("videoElement"); // Autoplay the video if application is visible if (document.visibilityState == "visible") { videoElement.play(); } // Handle page visibility change events function handleVisibilityChange() { if (document.visibilityState == "hidden") { videoElement.pause(); } else { videoElement.play(); } } document.addEventListener( "visibilitychange", handleVisibilityChange, false );requestIdleCallback API - 充分利用资源
使用 requestIdleCallback() 在浏览器空闲时运行高耗时、低优先级的任务
timeRemaining() 函数,用于获取任务可利用的空闲时间
javascriptfunction refinePi(deadline) { while (deadline.timeRemaining() > 0) { if (piStep()) pointsInside++; pointsTotal++; } currentEstimate = (4 * pointsInside) / pointsTotal; textElement = document.getElementById("piEstimate"); textElement.innerHTML = "Pi Estimate: " + currentEstimate; requestId = window.requestIdleCallback(refinePi); } function start() { requestId = window.requestIdleCallback(refinePi); }
Beacon - 数据上报
同步 xhr
对于开发者来说保证在文档卸载期间发送数据一直是一个困难,因为用户代理通常会忽略在 unload 事件处理器中产生的异步 XMLHttpRequest
为了解决这个问题,通常要在 unload 或者 beforeunload 事件处理器中发起一个同步 XMLHttpRequest,迫使用户代理延迟卸载文档,使得下一个导航出现的更晚,而下一个页面对于这种较差的载入表现无能为力
navigator.sendBeacon()
会使用户代理在有机会时异步地向服务器发送数据,同时不会延迟页面的卸载或影响下一导航的载入性能,如浏览器不兼容,则使用方法 1
javascriptwindow.addEventListener("unload", logData, false); function logData() { navigator.sendBeacon("/log", analyticsData);//analyticsData 参数是将要发送的 ArrayBufferView 或 Blob, DOMString 或者 FormData 类型的数据。 }发送不成功(415,405),可能是content-type不对,使用如下方式
javascriptsendBlob(url,data){ var params = new URLSearchParams(); for(let key in data){ params.set(key,JSON.stringify(data[key])); } var headers = { type: 'application/x-www-form-urlencoded' }; var blob = new Blob([params], headers); console.log(blob) navigator.sendBeacon(url, blob); }
webWorker 与 serviceWorker
参考链接:
详解:
web worker
js 单线程使多核 CPU 产生性能浪费,主线程(UI)可以创建 Worker 线程,复杂高延时的计算任务让 Worker 在后台负责,互不影响并返回结果。
Worker 创建成功后会始终运行,为免耗费资源,应在使用完后关闭。
注意:
- Worker 的 js 需与主线程 js 同源
- 不能使用 DOM(document,window),可以使用(navigator,location)
- Worker 与主线程需借助“消息”通信
- 不能使用 alert 和 console,能使用 xhr
- 不能读取 file://开头的本地文件,但能读取网络文件
基本用法:
index.html
html<!DOCTYPE html> <html> <head> <title>Web Workers basic example</title> </head> <body> <h1>Web Workers basic example</h1> <div class="controls" tabindex="0"> <form> <div> <label for="number1">Multiply number 1: </label> <input type="text" id="number1" value="0" /> </div> <div> <label for="number2">Multiply number 2: </label> <input type="text" id="number2" value="0" /> </div> </form> <p class="result">Result: 0</p> </div> <script src="main.js"></script> </body> </html>main.js
javascriptconst first = document.querySelector("#number1"); const second = document.querySelector("#number2"); const result = document.querySelector(".result"); if (window.Worker) { //调用Worker()构造函数,新建一个 Worker 线程,worker.js需位于网络位置,如localhost const myWorker = new Worker("worker.js"); first.onchange = function () { //主线程调用worker.postMessage()方法,向 Worker 发消息 myWorker.postMessage([first.value, second.value]); console.log("Message posted to worker"); }; second.onchange = function () { myWorker.postMessage([first.value, second.value]); console.log("Message posted to worker"); }; myWorker.onmessage = function (e) { //主线程通过worker.onmessage指定监听函数,接收子线程发回来的消息 result.textContent = e.data; console.log("Message received from worker"); }; //Worker 完成任务以后,主线程就可以把它关掉。 //worker.terminate();//由于这里onchange调用,需要一直运行worker //监听 Worker 是否发生错误 worker.onerror(function (event) { console.log( [ "ERROR: Line ", e.lineno, " in ", e.filename, ": ", e.message, ].join("") ); }); // 或者 worker.addEventListener("error", function (event) { // ... }); } else { console.log("Your browser doesn't support web workers."); }worker.js
javascript//Worker 线程内部需要有一个监听函数,监听message事件。 //4种等价写法: //1. this.addEventListener('message', function (e)... //2. self.addEventListener('message', function (e)... //3. addEventListener('message', function (e)... //4. onmessage = function(e)... onmessage = function (e) { console.log("Worker: Message received from main script"); let result = e.data[0] * e.data[1]; if (isNaN(result)) { postMessage("Please write two numbers"); } else { let workerResult = "Result: " + result; console.log("Worker: Posting message back to main script"); postMessage(workerResult); } }; //加载其它worker脚本 //importScripts('script1.js', 'script2.js'); //关闭 Worker //self.close();
service worker
Service Worker 可理解为一个介于客户端和服务器之间的一个代理服务器,可以拦截客户端的请求、向客户端发送消息、向服务器发起请求等等,其中最重要的作用之一就是离线资源缓存,这是原生APP 本来就支持的功能,这也是相比于 web app ,原生 app 更受青睐的主要原因。
兼容性:chrome,firefox,edge17+,safari11.1+
不能访问 DOM
postMessage 传递数据
不阻塞主线程
Service Worker 是一个浏览器中的进程而不是浏览器内核下的线程,注册后可在多个页面使用
service worker 能做些什么
后台消息传递
网络代理,转发请求,伪造响应
离线缓存
消息推送
生命周期
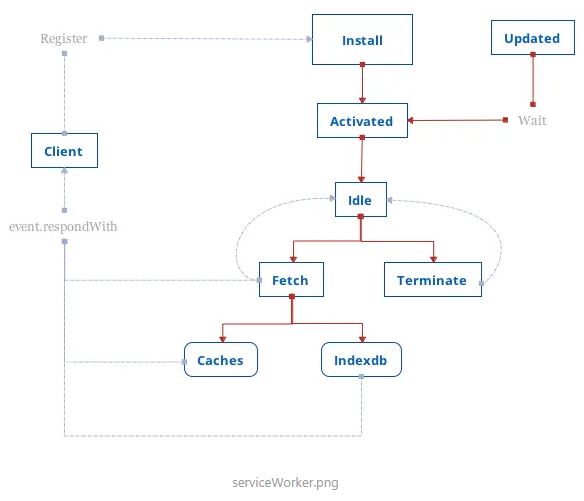
- register:client 端发起 register,注册 serviceWorker。
- install:注册成功后立即触发 install 事件。
- activate:安装后要等待激活 activated 事件,install 后不会立即触发 activated 事件。
- idle:activate 后对 client 的请求进行拦截处理,使用 fetch api。
- 默认不会带上 cookie,若想带上,需设置
- 跨域资源需设置
- terminate:长时间闲置,浏览器会暂停。
- caches:只能缓存 GET & HEAD 的请求,POST 等类型请求,返回数据可以保存在 indexDB 中
基本用法: index.js
javascriptif ("serviceWorker" in window.navigator) { //register(文件路径(相对于Origin,非当前js文件的目录),scope属性(控制内容子目录)) navigator.serviceWorker .register("/sw1/serviceWorker1.js", { scope: "./sw1" }) .then(function (reg) { console.log("success", reg); //发送信息 navigator.serviceWorker.controller.postMessage( "this message is from page" ); //如果使用的 scope 不是 Origin,会为null,此时可使用下面的方法 reg.active.postMessage("this message is from page, to sw"); //reg.active 就是被注册后激活 Serivce Worker 实例,由于 Service Worker 的激活是异步的,因此第一次注册 Service Worker 的时候,Service Worker 不会被立刻激活,reg.active 为 null,需要用到Promise,参考下方sw2 //MessageChannel指定端口,双向通信 const messageChannel = new MessageChannel(); messageChannel.port1.onmessage = (e) => { console.log(e.data); }; reg.active.postMessage("this message is from page, to sw", [ messageChannel.por2, ]); }) .catch(function (err) { console.log("fail", err); }); //可注册多个serviceWorker,只需scope不同 navigator.serviceWorker .register("/sw2/serviceWorker2.js", { scope: "./sw2" }) .then(function (reg) { //reg.active 为 null的Promise参考此处 return new Promise((resolve, reject) => { const interval = setInterval(function () { if (reg.active) { clearInterval(interval); resolve(reg.active); } }, 100); }); }) .then((sw) => { sw.postMessage("this message is from page, to sw2"); }) .catch(function (err) { console.log("fail", err); }); //接收信息 navigator.serviceWorker.addEventListener("message", function (e) { console.log(e.data); }); }serviceWorker.js(可在 chrome-调试-application 中调试)
javascript//接收信息 this.addEventListener('message', function (event) { console.log(event.data); //向消息的来源页面发送信息 event.source.postMessage('this message is from sw.js, to page'); //MessageChannel指定端口,双向通信 event.ports[0].onmessage = e => { console.log('sw:', e.data); // sw: this message is from sw2.js } event.ports[0].postMessage('this message is from sw.js'); }); //获取其他的页面,并发送消息 this.clients.matchAll().then(client => { client[0].postMessage('this message is from sw.js, to page'); }) //缓存指定静态资源 this.addEventListener('install', function (event) { console.log('Service Worker install'); //缓存是异步行为event.waitUntil保证资源被缓存完成前 Service Worker 不会被安装完成,避免发生错误 event.waitUntil( //CacheStroage 在浏览器中的接口名是 caches //caches.open 方法新建或打开一个已存在的缓存 caches.open('sw_demo').then(function (cache) { //cache.addAll请求指定链接的资源并把它们存储到之前打开的缓存中 return cache.addAll([ '/style.css', '/panda.jpg', './main.js' ]) } )); }); //动态缓存静态资源 //监听 fetch 事件,每当用户向服务器发起请求的时候这个事件就会被触发 //页面的路径不能大于 Service Worker 的 scope,不然 fetch 事件是无法被触发的 this.addEventListener('fetch', function (event) { console.log(event.request.url); //respondWith可以劫持用户发出的 http 请求,并把一个 Promise 作为响应结果返回给用户 event.respondWith( //使用用户的请求对 Cache Stroage 进行匹配 caches.match(event.request).then(res => { return res ||//匹配失败,则向服务器请求资源res返回给用户 fetch(event.request) .then(responese => { //匹配成功,则返回存储在缓存中的资源 const responeseClone = responese.clone(); caches.open('sw_demo').then(cache => { //cache.put 把新的资源存储在缓存中 cache.put(event.request, responeseClone); }) return responese; }) .catch(err => { console.log(err); }); }) ) //注意: //1. 第一次访问页面,资源的请求早于 Service Worker 的安装,所以静态资源是无法缓存的;只有当 Service Worker 安装完毕,第二次访问页面的时候,这些资源才会被缓存起来 //2. Cache Stroage 只能缓存静态资源,所以它只能缓存用户的 GET 请求 //3. Cache Stroage 中的缓存不会过期,但是浏览器对它的大小是有限制的,所以需要定期进行清理 //POST请求也可以在拦截后,通过判断请求中携带的 body 的内容来进行有选择的返回 if(event.request.method === 'POST') { event.respondWith( new Promise(resolve => { event.request.json().then(body => { console.log(body); // 用户请求携带的内容 }) resolve(new Response({ a: 2 })); // 返回的响应 }) )} } //对于静态资源的缓存,Cache Stroage 是个不错的选择;而对于数据,我们可以使用 IndexedDB 来存储,同样是拦截用户请求后,使用缓存在 IndexDB 中的数据作为响应返回 }); //更新 Cache Stroage //当有新的 service worker 文件存在的时候,他会被注册和安装,等待使用旧版本的页面全部被关闭后,才会被激活。这时候,我们就需要清理下我们的 Cache Stroage 了,删除旧版本的 Cache Stroage 。 this.addEventListener('install', function (event) { console.log('install'); event.waitUntil( caches.open('sw_demo_v2').then(function (cache) { // 更换 Cache Stroage return cache.addAll([ '/style.css', '/panda.jpg', './main.js' ]) } )) }); const cacheNames = [[sw_demo_v2']; // Cahce Stroage 白名单 this.addEventListener('activate', function (event) { event.waitUntil( caches.keys().then(keys => { return Promise.all[keys.map(key => { if (!cacheNames.includes(key)) { console.log(key); return caches.delete(key); // 删除不在白名单中的 Cache Stroage } })] }) ) }); //首先在安装 Service Worker 的时候,要换一个 Cache Stroage 来存储,然后设置一个白名单,当 Service Worker 被激活的时候,将不在白名单中的 Cache Stroage 删除,释放存储空间。同样使用 event.waitUntil ,在 Service Worker 被激活前执行完删除操作。应用场景
可行性
- Service Worker 有自己独立的工作线程,与网页区分开,网页崩溃了,Service Worker 一般情况下不会崩溃;
- Service Worker 生命周期一般要比网页还要长,可以用来监控网页的状态;
- 网页可以通过 navigator.serviceWorker.controller.postMessage API 向掌管自己的 SW 发送消息。
实现
- 网页加载后,通过 postMessageAPI 每 5s 给 sw 发送一个心跳,表示自己的在线,sw 将在线的网页登记下来,更新登记时间;
- 网页在 beforeunload 时,通过 postMessageAPI 告知自己已经正常关闭,sw 将登记的网页清除;
- 如果网页在运行的过程中 crash 了,sw 中的 running 状态将不会被清除,更新时间停留在奔溃前的最后一次心跳;
- Service Worker 每 10s 查看一遍登记中的网页,发现登记时间已经超出了一定时间(比如 15s)即可判定该网页 crash 了。
浏览器进程与线程
参考链接
详解
浏览器是多进程的
Browser 进程:浏览器的主进程,唯一,负责创建和销毁其它进程、网络资源的下载与管理、浏览器界面的展示、前进后退等。
GPU 进程:用于 3D 绘制等,最多一个。
第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建。
浏览器渲染进程(浏览器内核):内部是多线程的,每打开一个新网页就会创建一个进程,主要用于页面渲染,脚本执行,事件处理等。
GUI 渲染线程:负责渲染浏览器界面,当界面需要重绘(Repaint)或由于某种操作引发回流(Reflow)时,该线程就会执行。
JavaScript 引擎线程:也称为 JavaScript 内核,负责处理 Javascript 脚本程序、解析 Javascript 脚本、运行代码等。
- 注意:GUI 渲染线程与 JavaScript 引擎线程是互斥的,当 JavaScript 引擎执行时 GUI 线程会被挂起,GUI 更新会被保存在一个队列中等到 JavaScript 引擎空闲时立即被执行。所以如果 JavaScript 执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
事件触发线程:用来控制浏览器事件循环,当事件被触发时,该线程会把事件添加到待处理队列的队尾,等待 JavaScript 引擎的处理。
定时触发器线程:setInterval 与 setTimeout 所在线程,W3C 在 HTML 标准中规定 setTimeout 中低于 4ms 的时间间隔算为 4ms 。
异步 http 请求线程:在 XMLHttpRequest 连接后通过浏览器新开一个线程请求,将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由 JavaScript 引擎执行。
代码分割提高代码使用率
参考链接:
详解
代码利用率
概念
代码利用率 = 页面中实际被执行的代码 / 页面中引入的代码 * 100%
查看方式
chrome F12 - Cmd + Shift + P or Ctrl + Shift + P - "show Coverage" - 面板 reload
代码分割
概念
将脚本中无需立即调用的代码在代码构建时转变为异步加载的过程。
原理
使用 webpack 的 import()进行异步加载资源
类型
静态分割
在代码中明确声明需要异步加载的代码。
javascriptconst getModal = () => import("./src/modal.js"); //每当调用一个声明了异步加载代码的变量时,它总是返回一个 Promise 对象。 getModal().then((module) => { //... }); //vue使用import,react使用react-loadable适用场景:
- 大的库或框架:页面初始化时不使用则不加载
- 临时资源:页面初始化通常不被使用的模态框,对话框等
- 路由:用户不会一下子看到所有页面,只把当前页面相关资源给用户
“动态”分割
在代码调用时根据当前的状态,「动态地」异步加载对应的代码块。
javascriptconst getTheme = (themeName) => import(`./src/themes/${themeName}`); // Webpack 会在构建时将声明的目录下的所有可能分离的代码都抽象为一个文件(contextModule 模块),无论最终调用哪个文件,本质上和静态代码分割一样,在请求一个早已准备好的静态文件。 if (window.feeling.stylish) { getTheme("stylish").then((module) => { module.applyTheme(); }); } else if (window.feeling.trendy) { getTheme("trendy").then((module) => { module.applyTheme(); }); }适用场景:
- A/B Test:无需引入无用 UI 代码
- 加载主题:根据用户的设置,动态加载主题
- 方便:动态分割比静态分割写更少代码
webpack 魔术注释
通过在 import 关键字后的括号中使用指定注释,我们可以对代码分割后的 chunk 有更多的控制权
javascript// index.js import ( /* webpackChunkName: “my-chunk-name” */ /* webpackMode: lazy */ /* webpackPrefetch: true */ './footer' ) // webpack.config.js { output: { filename: “bundle.js”, chunkFilename: “[name].lazy-chunk.js” } }
webpack5更新(简略常用)
- 参考链接:
- 详解
重要更新:最低支持的 Node.js 版本从 6 增加到 10.13.0(LTS)
- 不再为 Node.js 模块 自动引用 Polyfills
- 针对长期缓存的优化
- 确定的 Chunk、模块 ID 和导出名称,新增了长期缓存的算法
- 使用真正的文件内容哈希值,之前它 "只"使用内部结构的哈希值
- Web 平台的一些支持
- 自定义的 JSON 解析器
- 资源模块引用新语法:在浏览器中的原生 ECMAScript 模块中使用javascript
import url from "./image.png"//旧 new URL("./image.png", import.meta.url)//新 - 原生 Worker 支持
- 支持在请求中处理协议
- 支持data:。支持 Base64 或原始编码。import x from "data:text/javascript,export default 42"
- 支持file:。
- 支持http(s)。需要通过new webpack.experiments.s schemesHttp(s)UriPlugin()选择加入
- 支持请求中的片段。./file.js#fragment
- 异步模块:基于异步和 Promise 解析
- 构建优化
- tree-shaking
- 改善重新导出命名空间,export const b = 2;未使用会被删除
- 内部模块找出导出和引用之间的依赖关系,生产模式默认开启optimization.innerGraph(内部依赖图算法)
- sideEffects 优化:导出未被使用,省略其相关引入
- 允许消除未使用的 CommonJs 导出,并从 require() 调用中跟踪引用的导出名称
- 对于不同的文件系统,增加了一些奇怪的大小写的警告/错误
- 改进 target 配置
- 允许指定最低版本,如 "node10.13"
- SplitChunksPlugin代码块拆分与模块大小javascript
module.exports = { optimization: { splitChunks: { minSize: { javascript: 30000, webassembly: 50000, }, }, }, };
- tree-shaking
- 架构变更
入口文件的新增配置
入口文件除了字符串、字符串数组,也可以使用描述符进行配置
javascriptmodule.exports = { entry: { catalog: { import: './catalog.js', }, }, };可以定义输出的文件名,之前都是通过 output.filename 进行定义
javascriptmodule.exports = { entry: { about: { import: './about.js', filename: 'pages/[name][ext]' }, }, };热替换HMR 运行时已被重构为运行时模块,HotUpdateChunkTemplate 已被合并入 ChunkTemplate 中。新功能,无需迁移。
dns-prefetch
- 参考链接:
- 详解
概念
浏览器根据自定义的规则,提前去解析后面可能用到的域名,来加速网站的访问速度。简单来讲就是提前解析域名,以免延迟。
html<link rel="dns-prefetch" href="//wq.test.com">这个功能有个默认加载条件,所有的a标签的href都会自动去启用DNS Prefetching,不需要在head里面加上link手动设置的。但a标签的默认启动在HTTPS不起作用。
这时要使用 meta里面http-equiv来强制启动功能。
html<meta http-equiv="x-dns-prefetch-control" content="on">总结
- DNS Prefetching是提前加载域名解析的,省去了解析时间。a标签的href是可以在chrome。firefox包括高版本的IE,但是在HTTPS下面不起作用,需要meta来强制开启功能
- 这是DNS的提前解析,并不是css,js之类的文件缓存,大家不要混淆了两个不同的概念。
- 如果直接做了js的重定向,或者在服务端做了重定向,没有在link里面手动设置,是不起作用的。
- 类似taobao的网页引用了大量很多其他域名的资源,如果所有的资源都在你本域名下,那么这个基本没有什么作用。因为DNS Chrome在访问你的网站就帮你缓存了。
SPA优化首屏
- 参考链接:
- 详解
- 将公用的JS库通过script标签外部引入,减小app.bundel的大小,让浏览器并行下载资源文件,提高下载速度;
- 在配置 路由时,页面和组件使用懒加载的方式引入,进一步缩小 app.bundel 的体积,在调用某个组件时再加载对应的js文件;
- root中插入loading 或者 骨架屏 prerender-spa-plugin,提升用户体验;
- 如果在webview中的页面,可以进行页面预加载
- 独立打包异步组件公共 Bundle,以提高复用性&缓存命中率
- 静态文件本地缓存,有两种方式分别为HTTP缓存,设置Cache-Control,Last-Modified,Etag等响应头和Service Worker离线缓存
- 配合 PWA 使用
- SSR
- root中插入loading 或者 骨架屏 prerender-spa-plugin
- 使用 Tree Shaking 减少业务代码体积
前端SEO与踩过的坑
参考链接:
详解
可优化的地方
- 图片加 alt 标签,除了在图片加载不出来能显示文字,还能有机会使搜索引擎索引到网站
- 避免使用 iframe,搜索引擎不会抓取到 iframe 里的内容,还要处理 iframe 滚动条问题
- 设置 title 可使鼠标悬停时出现提示文字
- 如果 hover 不触发动作,只改变样式,一般写在 css 里,如控制显示和隐藏,合理利用+(第一个兄弟元素)、~(后面所有兄弟元素)会有更好的效果
- cdn 与负载均衡
- 404、500 等页面自定义
- 事件委托,通常用于 ul-li,事件绑定在父元素,通过判断 event.target.nodeName 再执行动作,优于每个子元素都绑定事件,因为增删子元素会影响事件绑定
- 图片懒加载
- font-spider 按需打包字体
- gulp/webpack 打包压缩
- 合理利用 localstorage,避免重复请求
- service worker 执行高耗时任务
- 带动画的下拉标签和提交按钮防抖,参考章节节流和防抖
- form 添加随机串配合 session 防 csrf
- 父元素 overflow:hidden 清除浮动
- 多线程打包 happypack
- splitChunks 抽离公共文件
- sourceMap 生成
- 减少请求个数
- 使用cdn
分类优化
SEO优化
- 合理的 title 、 description 、 keywords :搜索对着三项的权重逐个减⼩, title值强调重点即可,重要关键词出现不要超过2次,⽽且要靠前,不同⻚⾯ title 要有所不同; description 把⻚⾯内容⾼度概括,⻓度合适,不可过分堆砌关键词,不同⻚⾯description 有所不同; keywords 列举出重要关键词即可
- 语义化的 HTML 代码,符合W3C规范:语义化代码让搜索引擎容易理解⽹⻚
- 重要内容 HTML 代码放在最前:搜索引擎抓取 HTML 顺序是从上到下,有的搜索引擎对抓取⻓度有限制,保证重要内容⼀定会被抓取
- 重要内容不要⽤ js 输出:爬⾍不会执⾏js获取内容
- 少⽤ iframe :搜索引擎不会抓取 iframe 中的内容
- ⾮装饰性图⽚必须加 alt
- 提⾼⽹站速度:⽹站速度是搜索引擎排序的⼀个重要指标
server优化
- 减少HTTP请求,合并文件、雪碧图
- 减少DNS查询,使用缓存
- 减少Dom元素的数量
- 使用CDN
- 配置ETag,http缓存的手段
- 对组件使用Gzip压缩
- 减少cookie的大小
css优化
- 将样式表放在页面顶部
- 使用less scss表达式
- 使用link 不适用@import引入样式
- 压缩css
- 禁⽌使⽤ gif 图⽚实现 loading 效果(降低 CPU 消耗,提升渲染性能)
- 使⽤ CSS3 代码代替 JS 动画(尽可能避免重绘重排以及回流)
- 对于⼀些⼩图标,可以使⽤base64位编码,以减少⽹络请求。
- ⻚⾯头部的 style script 会阻塞⻚⾯;(因为 Renderer进程中 JS 线程和渲染线程是互斥的)
- 当需要设置的样式很多时设置 className ⽽不是直接操作 style
js方面
- 将脚本放到页面底部
- 将js 外部引入
- 压缩js
- 使用Eslint语法检测
- 减少Dom的操作
- 熟练使用设计模式
- 禁⽌使⽤ iframe (阻塞⽗⽂档 onload 事件)
- ⻚⾯中空的 href 和 src 会阻塞⻚⾯其他资源的加载
- ⽹⻚ gzip , CDN 托管, data 缓存 ,图⽚服务器
webpack优化点
- 代码压缩插件 UglifyJsPlugin
- 服务器启⽤gzip压缩
- 按需加载资源⽂件 require.ensure
- 优化 devtool 中的 source-map
- 剥离 css ⽂件,单独打包
- 去除不必要插件,通常就是开发环境与⽣产环境⽤同⼀套配置⽂件导致
- 开发环境不做⽆意义的⼯作如提取 css 计算⽂件hash等
- 配置 devtool
- 优化构建时的搜索路径 指明需要构建⽬录及不需要构建⽬录
其他优化点
- CDN 缓存更⽅便
- 突破浏览器并发限制
- 节约 cookie 带宽
- 节约主域名的连接数,优化⻚⾯响应速度
- 防⽌不必要的安全问题
前端需要注意哪些 SEO
- 合理的 title、description、keywords:搜索对着三项的权重逐个减小,title 值强调重点即可,重要关键词出现不要超过 2 次,而且要靠前,不同页面 title 要有所不同;description 把页面内容高度概括,长度合适,不可过分堆砌关键词,不同页面 description 有所不同;keywords 列举出重要关键词即可 语义化的 HTML 代码,符合 W3C 规范:语义化代码让搜索引擎容易理解网页
- 重要内容 HTML 代码放在最前:搜索引擎抓取 HTML 顺序是从上到下,有的搜索引擎对抓取长度有限制,保证重要内容一定会被抓取
- 重要内容不要用 js 输出:爬虫不会执行 js 获取内容
- 少用 iframe(搜索引擎不会抓取 iframe 中的内容)
- 非装饰性图片必须加 alt
- 提高网站速度(网站速度是搜索引擎排序的一个重要指标)
兼容性问题
- IE/safari 解析日期格式,2020-1-3 无效,但 2020/1/3 2020-01-03 有效
- IE 不兼容 flex
- ios 移动端视频播放总是全屏,试试 playsinline
- iOS 浏览器在设置 overflow: scroll;后滑动不流畅,试试-webkit-overflow-scrolling: touch;
- document.documentElement 与 document.body 各浏览器获取有差异,赋值使用:var scrollTop = document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;
- 在iPhone8,ios12的条件下,点击收缩键盘后,页面不能自动回滚至初始状态。需要js:window.scrollTo(0,0)主动移动位置。
踩过的坑
- 高度百分比对响应式轮播无效,要使用 border-box 和 padding-bottom
- 行内元素(如 img,canvas)下方有白边,要加 display:block 消除
- position:relative 可以调节子元素全部位于父元素内,但如果所有子元素相加的高度大于父元素高度,会使父元素变高,固定父元素高度和溢出隐藏无效
- 视频不能 autoplay,试试 muted
- 移动端视频一般使用默认 controls,因为适配起来太麻烦了
- 元素在设置为 display:inline-block;后元素之间会产生间距,试试父元素添加 font-size: 0;
- vue 在 beforeRouteEnter 获取不到 this,javascript
beforeRouteEnter(to, from, next){ next((vm)=>{ console.log(vm); if(from.path == '/'){ vm.isShowAppr = false; } }); }, - vue 中 this.$route与this.$router 的区别:route 与 url 相关,router 与跳转相关
- angular 修改数据后页面没变化,试试 ChangeDetectorRef 中的 detectChanges 方法
- date.getMonth()是从 0 开始的
- 移动端字体最小 12px,再小只能通过 scale
- table 的 td 悬停设置 border 出现抖动问题,试试 td 和 tr 定高,如果不定高试试 outline,如果浏览器不兼容,只能改为 div
- 文本溢出显示省略号:css
单行 p { overflow: hidden; text-overflow: ellipsis; white-space: nowrap; } 多行(webkit) p { dispaly: -webkit-box; -webkit-box-orient: vertical; text-overflow: ellipsis; -webkit-line-clamp: 2; //显示几行 overflow: hidden; } 多行(兼容) p { position: relative; line-height: 1.4em; //要显示三行的话那么元素的高度就是行高的3倍,其它情况以此类推。 /* 3 times the line-height to show 3 lines */ height: 4.2em; overflow: hidden; } p::after { content: "..."; font-weight: bold; position: absolute; bottom: 0; right: 0; padding: 0 20px 1px 45px; } - 子元素绝对定位跟随父元素 overflow:scroll 滚动问题:出现这样的问题就是因为父元素设置了 position: relative;, 父元素相对定位会导致,滚动条在滚动的同时,将父元素的位置也移动了。解决办法:固定区与滚动区分离,滚动区用 div 包裹。
- 移动端chrome font-boosting
常用网站
性能检测与优化
构建策略
- 减少打包时间:缩减范围、缓存副本、定向搜索、提前构建、并行构建、可视结构
- 减少打包体积:分割代码、摇树优化、动态垫片、按需加载、作用提升、压缩资源
性能检测
- NetWork
- webpack-bundle-analyzerjavascript
npm install --save-dev webpack-bundle-analyzer const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin; module.exports = { plugins: [ new BundleAnalyzerPlugin() ] } - Performance
- PerformanceNavigationTimingjavascript
function showNavigationDetails() { const [entry] = performance.getEntriesByType("navigation"); console.table(entry.toJSON()); } - 抓包
- 性能测试工具
- Pingdom
- Load Impact
- WebPage Test
- Octa Gate Site Timer
- Free Speed Test
优化方法
include/exclude缩小Loader对文件的搜索范围,避免不必要的转译
javascriptexport default { // ... module: { rules: [{ exclude: /node_modules/, include: /src/, test: /\.js$/, use: "babel-loader" }] } };缓存编译副本,再次编译时只编译修改过的文件
大部分Loader/Plugin都会提供一个可使用编译缓存的选项,通常包含cache字眼。以babel-loader和eslint-webpack-plugin为例。
javascriptimport EslintPlugin from "eslint-webpack-plugin"; export default { // ... module: { rules: [{ // ... test: /\.js$/, use: [{ loader: "babel-loader", options: { cacheDirectory: true } }] }] }, plugins: [ new EslintPlugin({ cache: true }) ] };配置resolve提高文件的搜索速度,定向指定必须文件路径
javascriptexport default { // ... resolve: { alias: { "#": AbsPath(""), // 根目录快捷方式 "@": AbsPath("src"), // src目录快捷方式 swiper: "swiper/js/swiper.min.js" }, // 模块导入快捷方式 extensions: [".js", ".ts", ".jsx", ".tsx", ".json", ".vue"] // import路径时文件可省略后缀名 } };配置DllPlugin将第三方依赖提前打包,将DLL与业务代码完全分离且每次只构建业务代码
告知构建脚本哪些依赖做成DLL并生成DLL文件和DLL映射表文件
javascriptimport { DefinePlugin, DllPlugin } from "webpack"; export default { // ... entry: { vendor: ["react", "react-dom", "react-router-dom"] }, mode: "production", optimization: { splitChunks: { cacheGroups: { vendor: { chunks: "all", name: "vendor", test: /node_modules/ } } } }, output: { filename: "[name].dll.js", // 输出路径和文件名称 library: "[name]", // 全局变量名称:其他模块会从此变量上获取里面模块 path: AbsPath("dist/static") // 输出目录路径 }, plugins: [ new DefinePlugin({ "process.env.NODE_ENV": JSON.stringify("development") // DLL模式下覆盖生产环境成开发环境(启动第三方依赖调试模式) }), new DllPlugin({ name: "[name]", // 全局变量名称:减小搜索范围,与output.library结合使用 path: AbsPath("dist/static/[name]-manifest.json") // 输出目录路径 }) ] };在package.json里配置执行脚本且每次构建前首先执行该脚本打包出DLL文件
javascript{ "scripts": { "dll": "webpack --config webpack.dll.js" } }链接DLL文件并告知webpack可命中的DLL文件让其自行读取。使用html-webpack-tags-plugin在打包时自动插入DLL文件。
javascriptimport { DllReferencePlugin } from "webpack"; import HtmlTagsPlugin from "html-webpack-tags-plugin"; export default { // ... plugins: [ // ... new DllReferencePlugin({ manifest: AbsPath("dist/static/vendor-manifest.json") // manifest文件路径 }), new HtmlTagsPlugin({ append: false, // 在生成资源后插入 publicPath: "/", // 使用公共路径 tags: ["static/vendor.dll.js"] // 资源路径 }) ] };配置Thread将Loader单进程转换为多进程,释放CPU多核并发的优势
javascriptimport Os from "os"; export default { // ... module: { rules: [{ // ... test: /\.js$/, use: [{ loader: "thread-loader", options: { workers: Os.cpus().length } }, { loader: "babel-loader", options: { cacheDirectory: true } }] }] } };配置BundleAnalyzer分析打包文件结构,找出导致体积过大的原因
javascriptimport { BundleAnalyzerPlugin } from "webpack-bundle-analyzer"; export default { // ... plugins: [ // ... BundleAnalyzerPlugin() ] };tree shaking:清除无用代码
split chunks分割各个模块代码,提取相同部分代码,好处是减少重复代码的出现频率
javascriptexport default { // ... optimization: { runtimeChunk: { name: "manifest" }, // 抽离WebpackRuntime函数 splitChunks: { cacheGroups: { common: { minChunks: 2, name: "common", priority: 5, reuseExistingChunk: true, // 重用已存在代码块 test: AbsPath("src") }, vendor: { chunks: "initial", // 代码分割类型 name: "vendor", // 代码块名称 priority: 10, // 优先级 test: /node_modules/ // 校验文件正则表达式 } }, // 缓存组 chunks: "all" // 代码分割类型:all全部模块,async异步模块,initial入口模块 } // 代码块分割 } };通过补丁服务根据UA返回当前浏览器代码补丁,好处是无需将繁重的代码补丁打包进去
官方CDN服务:https://polyfill.io/v3/polyfill.min.js 阿里CDN服务:https://polyfill.alicdn.com/polyfill.min.js
使用html-webpack-tags-plugin在打包时自动插入动态垫片
javascriptimport HtmlTagsPlugin from "html-webpack-tags-plugin"; export default { plugins: [ new HtmlTagsPlugin({ append: false, // 在生成资源后插入 publicPath: false, // 使用公共路径 tags: ["https://polyfill.alicdn.com/polyfill.min.js"] // 资源路径 }) ] };按需加载
将路由页面/触发性功能单独打包为一个文件,使用时才加载,减轻首屏渲染的负担
javascriptconst Login = () => import( /* webpackChunkName: "login" */ "../../views/login"); const Logon = () => import( /* webpackChunkName: "logon" */ "../../views/logon");在package.json的babel相关配置里接入@babel/plugin-syntax-dynamic-import
javascript{ // ... "babel": { // ... "plugins": [ // ... "@babel/plugin-syntax-dynamic-import" ] } }作用提升:分析模块间依赖关系,把打包好的模块合并到一个函数中,好处是减少函数声明和内存花销
javascriptexport default { // ... mode: "production" }; // 显式设置 export default { // ... optimization: { // ... concatenateModules: true } };压缩HTML/CSS/JS代码,压缩字体/图像/音频/视频
javascriptimport HtmlPlugin from "html-webpack-plugin"; export default { // ... plugins: [ // ... HtmlPlugin({ // ... minify: { collapseWhitespace: true, removeComments: true } // 压缩HTML }) ] };- optimize-css-assets-webpack-plugin:压缩CSS代码
- uglifyjs-webpack-plugin:压缩ES5版本的JS代码
- terser-webpack-plugin:压缩ES6版本的JS代码
javascriptimport OptimizeCssAssetsPlugin from "optimize-css-assets-webpack-plugin"; import TerserPlugin from "terser-webpack-plugin"; import UglifyjsPlugin from "uglifyjs-webpack-plugin"; const compressOpts = type => ({ cache: true, // 缓存文件 parallel: true, // 并行处理 [`${type}Options`]: { beautify: false, compress: { drop_console: true } } // 压缩配置 }); const compressCss = new OptimizeCssAssetsPlugin({ cssProcessorOptions: { autoprefixer: { remove: false }, // 设置autoprefixer保留过时样式 safe: true // 避免cssnano重新计算z-index } }); const compressJs = USE_ES6 ? new TerserPlugin(compressOpts("terser")) : new UglifyjsPlugin(compressOpts("uglify")); export default { // ... optimization: { // ... minimizer: [compressCss, compressJs] // 代码压缩 } };拆包
nginx配置gzip
图片压缩
- 智图压缩 (百度很难搜到官网了,免费、批量、好用)
- tinypng(免费、批量、速度块)
- fireworks工具压缩像素点和尺寸 (自己动手,掌握尺度)
- photoshop找UI压缩后发给你
图片分割,布局拼接(专题)
sprite:精灵图/雪碧图,合并icon到1张图
CDN
懒加载
iconfont:中文字体图
- 矢量
- 轻量
- 易修改
- 不占用图片资源请求。
font-spider:字体按需打包
逻辑先后合理:主请求前置,其余请求后置,防堵塞,防加载慢,防主体内容长期白屏
算法复杂度
单页面方面的优化
- vue简结.md->注意或优化的地方
- react简结.md->react性能优化
node middleware:node 中间件,中间件主要是指封装所有Http请求细节处理的方法。一次Http请求通常包含很多工作,如记录日志、ip过滤、查询字符串、请求体解析、Cookie处理、权限验证、参数验证、异常处理等,使用node middleware合并请求,减少请求次数。
web worker
缓存:浏览器缓存、CDN、反向代理、本地缓存、分布式缓存、数据库缓存
GPU渲染:css属性transform相关
Ajax可缓存:下一次调用Ajax发送相同的请求,直接从缓存中拿数据。
Resource Hints:资源预加载,基于 link 标签的 DNS-prefetch、subresource、preload、 prefetch、preconnect、prerender,和本地存储 localStorage
SSR:服务器端渲染,Vue的Nuxt.js和React的next.js
UNPKG:npm包进行CDN加速的站点,可以将一些比较固定了依赖写入html模版中,从而提高网页的性能。需要将这些依赖声明为external,以便webpack打包时不从node_modules中加载这些资源,配置如下:
javascriptexternals: { 'react': 'React' }将所依赖的资源写在html模版中,这一步需要用到html-webpack-plugin
javascript<% if (htmlWebpackPlugin.options.node_env === 'development') { %> <script src="https://unpkg.com/[email protected]/umd/react.development.js"></script> <% } else { %> <script src="https://unpkg.com/[email protected]/umd/react.production.min.js"></script> <% } %>浏览器缓存
- 考虑拒绝一切缓存策略:Cache-Control:no-store
- 考虑资源是否每次向服务器请求:Cache-Control:no-cache
- 考虑资源是否被代理服务器缓存:Cache-Control:public/private
- 考虑资源过期时间:Expires:t/Cache-Control:max-age=t,s-maxage=t
- 考虑协商缓存:Last-Modified/Etag
浏览器进程与线程
- 参考链接:
详解
进程与线程的概念
从本质上说,进程和线程都是 CPU 工作时间片的一个描述:
进程描述了 CPU 在运行指令及加载和保存上下文所需的时间,放在应用上来说就代表了一个程序。
线程是进程中的更小单位,描述了执行一段指令所需的时间。
进程是资源分配的最小单位,线程是CPU调度的最小单位。
一个进程就是一个程序的运行实例。详细解释就是,启动一个程序的时候,操作系统会为该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程,我们把这样的一个运行环境叫进程。进程是运行在虚拟内存上的,虚拟内存是用来解决用户对硬件资源的无限需求和有限的硬件资源之间的矛盾的。从操作系统角度来看,虚拟内存即交换文件;从处理器角度看,虚拟内存即虚拟地址空间。
如果程序很多时,内存可能会不够,操作系统为每个进程提供一套独立的虚拟地址空间,从而使得同一块物理内存在不同的进程中可以对应到不同或相同的虚拟地址,变相的增加了程序可以使用的内存。
* 进程和线程之间的关系有以下四个特点:
* 进程中的任意一线程执行出错,都会导致整个进程的崩溃。
* 线程之间共享进程中的数据。
* 当一个进程关闭之后,操作系统会回收进程所占用的内存, 当一个进程退出时,操作系统会回收该进程所申请的所有资源;即使其中任意线程因为操作不当导致内存泄漏,当进程退出时,这些内存也会被正确回收。
* 进程之间的内容相互隔离。 进程隔离就是为了使操作系统中的进程互不干扰,每一个进程只能访问自己占有的数据,也就避免出现进程 A 写入数据到进程 B 的情况。正是因为进程之间的数据是严格隔离的,所以一个进程如果崩溃了,或者挂起了,是不会影响到其他进程的。如果进程之间需要进行数据的通信,这时候,就需要使用用于进程间通信的机制了。
- Chrome 浏览器包括:
* 1 个浏览器主进程
主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
* 1 个 GPU 进程
GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。
* 1 个网络进程
主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
* 多个渲染进程
核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。
1. GUI渲染线程
负责渲染浏览器页面,解析HTML、CSS,构建DOM树、构建CSSOM树、构建渲染树和绘制页面;当界面需要重绘或由于某种操作引发回流时,该线程就会执行。
GUI渲染线程和JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起,GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
2. JS引擎线程
JS引擎线程也称为JS内核,负责处理Javascript脚本程序,解析Javascript脚本,运行代码;JS引擎线程一直等待着任务队列中任务的到来,然后加以处理,一个Tab页中无论什么时候都只有一个JS引擎线程在运行JS程序;
GUI渲染线程与JS引擎线程的互斥关系,所以如果JS执行的时间过长,会造成页面的渲染不连贯,导致页面渲染加载阻塞。
3. 时间触发线程
时间触发线程属于浏览器而不是JS引擎,用来控制事件循环;当JS引擎执行代码块如setTimeOut时(也可是来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件触发线程中;当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理;
由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行)
4. 定时器触发进程
定时器触发进程即setInterval与setTimeout所在线程;浏览器定时计数器并不是由JS引擎计数的,因为JS引擎是单线程的,如果处于阻塞线程状态就会影响记计时的准确性;因此使用单独线程来计时并触发定时器,计时完毕后,添加到事件队列中,等待JS引擎空闲后执行,所以定时器中的任务在设定的时间点不一定能够准时执行,定时器只是在指定时间点将任务添加到事件队列中;
W3C在HTML标准中规定,定时器的定时时间不能小于4ms,如果是小于4ms,则默认为4ms。
5. 异步http请求线程
XMLHttpRequest连接后通过浏览器新开一个线程请求;
检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将回调函数放入事件队列中,等待JS引擎空闲后执行;
* 多个插件进程
主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
所以,打开一个网页,最少需要四个进程:1 个网络进程、1 个浏览器进程、1 个 GPU 进程以及 1 个渲染进程。如果打开的页面有运行插件的话,还需要再加上 1 个插件进程。
* 虽然多进程模型提升了浏览器的稳定性、流畅性和安全性,但同样不可避免地带来了一些问题:
* 更高的资源占用:因为每个进程都会包含公共基础结构的副本(如 JavaScript 运行环境),这就意味着浏览器会消耗更多的内存资源。
* 更复杂的体系架构:浏览器各模块之间耦合性高、扩展性差等问题,会导致现在的架构已经很难适应新的需求了。
- 进程和线程的区别
* 进程可以看做独立应用,线程不能
* 资源:进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位);线程是cpu调度的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)。
* 通信方面:线程间可以通过直接共享同一进程中的资源,而进程通信需要借助 进程间通信。
* 调度:进程切换比线程切换的开销要大。线程是CPU调度的基本单位,线程的切换不会引起进程切换,但某个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
* 系统开销:由于创建或撤销进程时,系统都要为之分配或回收资源,如内存、I/O 等,其开销远大于创建或撤销线程时的开销。同理,在进行进程切换时,涉及当前执行进程 CPU 环境还有各种各样状态的保存及新调度进程状态的设置,而线程切换时只需保存和设置少量寄存器内容,开销较小。
- 进程之间的通信方式
1. 管道通信
管道是一种最基本的进程间通信机制。管道就是操作系统在内核中开辟的一段缓冲区,进程1可以将需要交互的数据拷贝到这段缓冲区,进程2就可以读取了。
* 管道的特点:
* 只能单向通信
* 只能血缘关系的进程进行通信
* 依赖于文件系统
* 生命周期随进程
* 面向字节流的服务
* 管道内部提供了同步机制
2. 消息队列通信
消息队列就是一个消息的列表。用户可以在消息队列中添加消息、读取消息等。消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法。 每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构。可以通过发送消息来避免命名管道的同步和阻塞问题。但是消息队列与命名管道一样,每个数据块都有一个最大长度的限制。
使用消息队列进行进程间通信,可能会收到数据块最大长度的限制约束等,这也是这种通信方式的缺点。如果频繁的发生进程间的通信行为,那么进程需要频繁地读取队列中的数据到内存,相当于间接地从一个进程拷贝到另一个进程,这需要花费时间。
3. 信号量通信
共享内存最大的问题就是多进程竞争内存的问题,就像类似于线程安全问题。我们可以使用信号量来解决这个问题。信号量的本质就是一个计数器,用来实现进程之间的互斥与同步。例如信号量的初始值是 1,然后 a 进程来访问内存1的时候,我们就把信号量的值设为 0,然后进程b 也要来访问内存1的时候,看到信号量的值为 0 就知道已经有进程在访问内存1了,这个时候进程 b 就会访问不了内存1。所以说,信号量也是进程之间的一种通信方式。
4. 信号通信
信号(Signals )是Unix系统中使用的最古老的进程间通信的方法之一。操作系统通过信号来通知进程系统中发生了某种预先规定好的事件(一组事件中的一个),它也是用户进程之间通信和同步的一种原始机制。
5. 共享内存通信
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问(使多个进程可以访问同一块内存空间)。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
6. 套接字通信
上面说的共享内存、管道、信号量、消息队列,他们都是多个进程在一台主机之间的通信,那两个相隔几千里的进程能够进行通信吗?答是必须的,这个时候 Socket 这家伙就派上用场了,例如我们平时通过浏览器发起一个 http 请求,然后服务器给你返回对应的数据,这种就是采用 Socket 的通信方式了。
- 僵尸进程和孤儿进程
* 孤儿进程
父进程退出了,而它的一个或多个进程还在运行,那这些子进程都会成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
* 僵尸进程
子进程比父进程先结束,而父进程又没有释放子进程占用的资源,那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵死进程。
- 死锁
所谓死锁,是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。
* 系统中的资源可以分为两类:
* 可剥夺资源,是指某进程在获得这类资源后,该资源可以再被其他进程或系统剥夺,CPU和主存均属于可剥夺性资源;
* 不可剥夺资源,当系统把这类资源分配给某进程后,再不能强行收回,只能在进程用完后自行释放,如磁带机、打印机等。
* 产生死锁的原因
1. 竞争资源
产生死锁中的竞争资源之一指的是竞争不可剥夺资源(例如:系统中只有一台打印机,可供进程P1使用,假定P1已占用了打印机,若P2继续要求打印机打印将阻塞)
产生死锁中的竞争资源另外一种资源指的是竞争临时资源(临时资源包括硬件中断、信号、消息、缓冲区内的消息等),通常消息通信顺序进行不当,则会产生死锁
2. 进程间推进顺序非法
若P1保持了资源R1,P2保持了资源R2,系统处于不安全状态,因为这两个进程再向前推进,便可能发生死锁。例如,当P1运行到P1:Request(R2)时,将因R2已被P2占用而阻塞;当P2运行到P2:Request(R1)时,也将因R1已被P1占用而阻塞,于是发生进程死锁
* 产生死锁的必要条件:
* 互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
* 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
* 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
* 环路等待条件:在发生死锁时,必然存在一个进程——资源的环形链。
* 预防死锁的方法:
* 资源一次性分配:一次性分配所有资源,这样就不会再有请求了(破坏请求条件)
* 只要有一个资源得不到分配,也不给这个进程分配其他的资源(破坏请保持条件)
* 可剥夺资源:即当某进程获得了部分资源,但得不到其它资源,则释放已占有的资源(破坏不可剥夺条件)
* 资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)